Every treatment center operator I talk to in 2026 has the same problem. They funded an AEO program three or six months ago because Google AI Overviews started eating their organic traffic, and now they cannot answer the CFO question: is it working? The operators who answer that question cleanly are the ones who pair citation measurement with a clear entity model for AI search, so each engine knows what their brand is before it decides to cite them.
Their rank tracker shows position drops. GA4 shows organic sessions down. Their agency keeps using the phrase “AI citation share” in the monthly call. Nobody can point to a single number that connects citation work to admits.
The measurement layer is the part of our AEO capability that operators ask about most often, and it is the part the market explains worst. The vendor pages all sell “visibility.” The agency reports all show a screenshot of a ChatGPT citation.
Neither shows whether the work is producing admissions outcomes you can defend at the board level.
This guide is the version I wish existed when our team was building the measurement stack for our own clients.
It covers what to track, which tool fits which operator, how citation traffic maps to the admit funnel, and what the monthly report needs to contain before a CMO will accept it.
Key Takeaways
- Traditional SEO tools miss the AI search layer. Rank trackers, GSC, and GA4 do not see AI citations. Operators reporting only on rankings and traffic are flying with one instrument.
- The measurement stack has three layers: citation tracking (which engines cite you on which prompts), attribution (how citation traffic flows into the admit funnel), and benchmarking (citation share versus competitors over time).
- The tool you pick depends on operator scale. Otterly fits solo marketers at $29-$489 per month. Peec AI and AthenaHQ fit mid-market at roughly $100-$300 per month. Profound and BrightEdge fit enterprise at $50K+ per year on annual contracts.
- Citation share alone is a vanity metric. Pair it with admit attribution data from GA4 plus your CRM, or the C-suite will not fund the program past the second quarter.
- A 25-50 prompt query set is enough to start. Tracking 500 prompts on day one wastes credits and obscures the signal. Pick the prompts that map to the modalities and insurance combinations that produce admits.
- AEO measurement is a 90-day instrument, not a 30-day instrument. Citation movement is monthly at the engine level. The earliest credible C-suite report happens at the end of month three.
- The agency reporting standard should include four blocks: citation share by engine, citation traffic attribution, competitor benchmark, and citation gap analysis. If your agency report is missing one of these, you are paying for a report that cannot defend the budget.
Part 1. Why traditional SEO measurement misses the AI search layer
The instruments most operators inherited from their traditional SEO program were built for a blue-link world. Google Search Console reports clicks and impressions for queries that produce a clicked result on the SERP.
GA4 reports sessions that arrive on your site. Rank trackers report your domain position for tracked keywords. None of these instruments observe what happens when ChatGPT answers a query by paraphrasing three sources and citing two of them.
None of them observe what happens when Perplexity answers a multi-part insurance question by surfacing your page in the citation strip but the user reads the answer and never clicks. None of them observe Google AI Overviews citing your page at the top of the answer block.
The blind spot is the entire AI search layer.
Google Search Central’s official guidance on optimizing for generative AI search confirms that AI Overviews and AI Mode now sit on top of the search experience for many user queries, with citation patterns that work differently from the ten blue links operators learned to optimize for.
Search Engine Journal’s analysis of that guidance surfaces the operational implication: Google treats “answer engine optimization” and “generative engine optimization” as continuations of SEO, not a separate discipline. Your measurement stack should follow the same logic.
The implication for measurement is direct. Your rank tracker, set up by a competent behavioral health SEO program, can show you at position 3 for “rehab Los Angeles” and your traffic can still be down 40 percent year-over-year, because the position-3 result is now below an AI Overview block that answers the query without sending a click.
Your page was used. You received no traffic credit. Your old measurement stack reports the position correctly and the conclusion incorrectly.
The fix is not to abandon the rank tracker. The fix is to add a second instrument that observes the AI citation layer, and to read both together. The AEO Ultimate Guide covers the production side of getting cited. This guide covers the observation side.
One more piece of context before we move into tools. AI citation behavior changes faster than blue-link ranking behavior. Engines update model weights weekly. Citation patterns that held in February shift by May.
Your measurement cadence has to match. Quarterly snapshots are too slow. Monthly is the floor.
Part 2. Layer 1: Citation tracking tools and what they measure
There are five real tools in this category as of mid-2026, plus a DIY framework that some operators run alongside or instead. The walk-through below covers what each one tracks, what it costs, and how it pairs with the fan-out query analysis that feeds your prompt set in the first place, what it costs, and what a behavioral health operator gets out of it.

Pricing is current as of the time this article was written. Vendor pricing in this category changes quarterly. Verify on the vendor site before signing a contract.
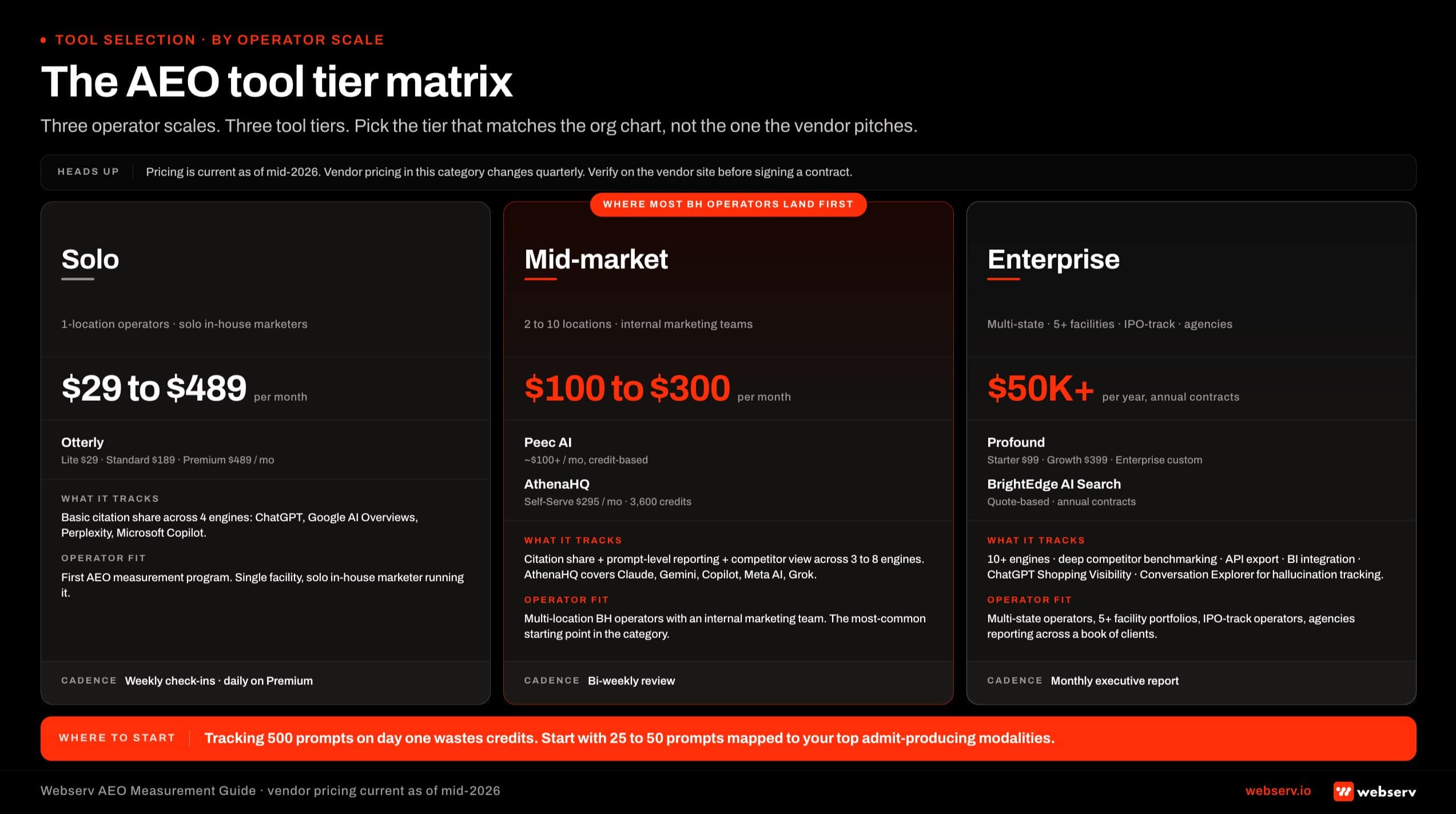
Profound: enterprise breadth, enterprise pricing
Profound tracks citation share across 10-plus AI engines including ChatGPT, Perplexity, Claude, Google AI Overviews, Gemini, Grok, and Meta AI. The platform has moved toward enterprise positioning in 2026, with Starter at $99 per month, Growth at $399 per month, and Enterprise on a custom quote.
Multi-platform coverage, API access, and SOC 2 features now sit on the Enterprise tier.
What you get on Enterprise: ChatGPT Shopping Visibility for retail-style queries, Content Agents that propose AEO-aligned content moves, and Conversation Explorer for catching brand hallucinations or inaccurate AI-generated claims about your facility. The breadth is unmatched. The price is the gating issue for any operator below the multi-location level.
Webserv view: Profound fits operators running five or more facilities or operators whose marketing budget includes a paid-search line above $50K per month. Below that scale, the math does not work and the breadth of engines tracked is more than the operator can act on.
AthenaHQ: credit-based, BH-suitable, ACE Citation Engine on Enterprise
AthenaHQ uses a credit-based model. The eight-engine view it produces only pays off if your pages are already structured around the semantic triples the engines need to cite cleanly. Self-Serve starts at $295 per month for 3,600 credits, where each AI response counts as one credit. Enterprise is custom. All plans track eight platforms: ChatGPT, Google AI Overviews, Perplexity, Claude, Gemini, Copilot, Meta AI, and Grok.
The ACE Citation Engine, API access, and BI integrations are Enterprise-only.
Self-Serve at 3,600 credits per month means you can run roughly 120 prompts per day across the eight engines, which is plenty for a single-location operator. The credit math is the part to understand.
A 25-prompt set tracked daily across all eight engines costs 200 credits per day, or 6,000 per month, which means you outgrow the Self-Serve tier in about two months if you are running the full engine set.
Webserv view: AthenaHQ is the BH-suitable mid-market default. The eight-engine coverage matches the actual citation surfaces a treatment center should care about. Step up to Enterprise when you need ACE attribution and API export, typically when you cross three or more locations.
Peec AI: entry-level mid-market, multilingual
Peec AI starts at $100 per month. The pricing model is credit-based: one prompt running against one model for a full month is 30 credits. Most operators track three engines, which works out to roughly 90 credits per prompt per month.
Add-on engines (Claude, Gemini, Grok, DeepSeek) run €20-30 per month each.
Default coverage is ChatGPT, Perplexity, and Google AI Overviews with daily tracking. The platform sells itself on multilingual coverage across 115-plus languages, which is not the typical treatment center use case but is useful for operators with bilingual landing pages or Spanish-language admissions content.
Webserv view: Peec AI is the right starting point for a single-location operator who wants daily tracking on the three highest-impact engines without committing to enterprise pricing. The cost ramps quickly once you add Claude and Gemini, which most operators end up wanting within the first quarter.
BrightEdge AI Search: enterprise, integrated with traditional SEO
BrightEdge does not publish list pricing. Contracts are quote-based and typically annual or multi-year. Independent buyer benchmarks put BrightEdge AI Search contracts at $50K-plus per year, and global multi-domain deployments can scale into the low six figures.
The pricing model is credit-based by keyword and SERP, with coverage across 170 countries baked in.
The argument for BrightEdge is integration. If you are already running BrightEdge for traditional SEO across an enterprise portfolio, the AI Search module sits inside the same platform and reports against the same keyword universe. The argument against it for treatment centers is scale mismatch.
Most behavioral health operators do not have the keyword universe size to justify the contract.
Webserv view: BrightEdge fits BH operators only at the multi-state portfolio level. For single-location or two-location operators, the dedicated AEO tools deliver a tighter citation view at one-tenth the cost.
Otterly: lightest, lowest entry price
Otterly, covered in our behavioral health marketing guide as the lightest entry-level instrument, is the lowest entry price of the tools listed here. Lite is $29 per month for 15 search prompts. Standard is $189 per month for 100 prompts. Premium is $489 per month for 400 prompts. Coverage includes ChatGPT, Google AI Overviews, Perplexity, and Microsoft Copilot.
Daily tracking is on the Premium plan.
The trade-off is depth. Otterly tracks four engines, not eight. The competitive view is thinner than what AthenaHQ or Profound deliver. The reporting layer is built for a single-marketer use case rather than an agency-managed program.
Webserv view: Otterly is the right tool for a solo in-house marketer running their first AEO measurement program with limited budget. It is not the right tool to run a multi-engine citation strategy on behalf of a portfolio operator.
Treat it as a 90-day instrument that gets replaced once the program proves out.
DIY framework: manual prompt rotation
The DIY framework, which only works when paired with the non-generic content production standard that earns citations in the first place, is a spreadsheet of 25-50 priority prompts, run manually against ChatGPT, Perplexity, Claude, and Google AI Overviews on the first business day of each month. The marketer pastes each prompt into each engine, screenshots the result, and logs whether the operator’s domain was cited.
The DIY method is real measurement. It is not scalable past a single-location operator. The advantage is zero tool cost and complete visibility into the actual answer text that the engines produce, which is information the paid tools sometimes abstract away.
The disadvantage is the 6-8 hours per month it takes to run.
If you are picking your first AEO measurement tool, do not optimize for engine count. Optimize for what you will actually act on. A 25-prompt set tracked across four engines beats a 500-prompt set tracked across ten engines you cannot read in a monthly meeting.
Trevor Gage, Director of Earned & Owned Media, Webserv
Part 3. Layer 2: Attribution: from AI citation to admit
The second layer is the part most agency reports skip. Citation share by itself is a vanity metric. It tells you the engines see you. It does not tell you the work is producing inquiries, assessments, or admissions. Attribution is the bridge.
The mechanical flow runs in four steps, and it sits inside the broader healthcare digital marketing analytics stack a treatment center should already be running. An AI engine cites your page in an answer. A user reads the answer, decides to follow the source link, and lands on your site. The user enters the funnel, typically through a form, phone call, or chat.
Your admissions operations team processes the contact, runs a verification of benefits, and either schedules an assessment or routes the contact elsewhere.
The attribution job is to label each of those four steps so you can read them as a funnel. GA4 carries some of the work. Your CRM carries the rest. The handoff between GA4 and the CRM is where most BH operators lose attribution credibility.
What GA4 can see
GA4, when configured against the CallRail attribution setup most BH operators run, sees referral traffic from chatgpt.com, perplexity.ai, claude.ai, and the AI Overviews surface inside google.com.
The referral signal is imperfect because some AI engines render answers inside the engine without sending a referrer header that GA4 reads cleanly, but most click-through traffic surfaces in the Source/Medium report under those domains.
The setup move: create a custom channel group in GA4 that buckets the AI engines into a single “AI Search” channel separated from “Organic Search” and “Referral.” This is a five-minute admin job that takes most operators six months to do because nobody owns it.
Until that channel exists, your monthly report is reporting AI traffic inside Organic Search and undercounting both channels.
What the CRM has to do
The handoff only works when your technical SEO foundation is firing the tracking events cleanly. The CRM picks up after the form submission or call. Every BH CRM I have audited captures lead source for paid search and traditional organic. Most of them do not have a clean field for AI citation traffic. The fix is one of two patterns.
Pattern A, UTM-based: a custom GA4 audience that flags AI-source sessions and fires a hidden form field with utm_source=ai-engine when the session converts. The CRM receives the UTM and stores it on the lead record. The admissions team can then segment “AI-sourced” leads in any future report.
Pattern B, referrer capture: a hidden form field that captures the actual referrer URL at form submission. The CRM receives a string like “chatgpt.com” or “perplexity.ai” on the lead record. Same outcome with a different implementation path.
Either pattern lets you close the loop from AI citation through to admit. Without one of them, the attribution conversation ends at the GA4 traffic report, which is a citation-traffic story, not an admit story.
The compliance note matters here. The HHS Office for Civil Rights bulletin on online tracking technologies confirms that IP addresses combined with health information constitute PHI under HIPAA when captured by HIPAA-regulated entities through digital surfaces.
The implication for AEO attribution: your setup has to respect the same constraints as your paid attribution stack. Do not pass health-condition slugs in UTM parameters. Do not store referrer strings that include condition keywords without server-side handling.
Part 4. Layer 3: Benchmarking: citation share vs competitors over time
Citation share against your own historical baseline is necessary. Citation share against your competitor set is what the CFO actually wants to see. Layer 3 is the comparative view that turns the measurement work from a status report into a competitive-position artifact.
How to define the query set
The query set is the universe of prompts you measure against. For a single-location BH operator with a keyword strategy already mapped to admit drivers, the right query set is 25-50 prompts covering the modalities, insurance combinations, and geographic anchors that drive admits.
Examples: “best PHP near me for adolescents with Aetna,” “rehab in Orange County that takes BCBS PPO,” “anxiety and substance use treatment Los Angeles.”
The mistake to avoid is tracking 300 prompts because the tool gives you the credits. A 300-prompt set produces a number that moves quarterly and tells you nothing about which specific service line is gaining or losing.
The 25-50 set tells you that Aetna-plus-PHP went from 12 percent citation share to 19 percent in February, which is information you can act on. The discipline mirrors the work in our topical authority framework: cover the right cluster, not every cluster.
How to define the competitor set
Pick five competitors maximum. Two should be operators of your scale in your region. Two should be regional or national operators a step above you (the ones the CMO benchmarks against in QBRs).
One should be a content competitor, an operator that does not compete for the same patient but ranks for the same informational queries and shows up in AI citations.
That five-name set is enough to make a competitive citation chart that a board member can read. Ten competitors produces a chart nobody reads. Three competitors produces a chart that does not pass smell-tests with a skeptical operator.
The cadence
Snapshot citation share on the first business day of each month. Run the same prompts. Read the share. Plot the trend across all five competitors and your domain. Three months of data is the minimum to say anything credible about direction.
Six months of data is the minimum to say anything credible about velocity.
One operator-experience note: the first three months will look noisy. AI engines update model weights between snapshots. Citation shares can swing 5-10 percentage points engine-over-engine before stabilizing. Resist the temptation to act on month-one or month-two data.
The signal lives at month three and beyond.
Part 5. The Webserv reporting template
The template below is the one we run for clients in our own AEO programs. It is monthly. It has four blocks. Every block has to be present or the report does not defend the budget.
Block 1: Citation share by AI engine
Run your 25-50 priority prompts across the engines your tool covers. Report citation share as a percent for each engine, calculated as the count of prompts where the operator’s domain appears in the citation list divided by the total count of prompts.
Show month-over-month delta. Show a six-month trend line if you have the data.
For ratio framing, mid-market BH operators with three to six months of AEO program work tend to land in the range of 8-18 percent citation share on Google AI Overviews and 5-15 percent on ChatGPT for their priority query sets.
Operators below those ranges are typically inside the first 90 days of program work. Operators above those ranges are typically running mature programs and competing for the top citation slot rather than initial inclusion.
Block 2: Citation traffic from GA4
Pull sessions from the AI Search channel you set up in Part 3. Report total sessions, sessions by source (chatgpt.com, perplexity.ai, etc.), and conversion events from the AI Search channel.
If your admissions handoff to the CRM is clean, also report leads tagged as AI-sourced.
Block 3: Competitor citation share
Same 25-50 prompts. Report the operator’s citation share alongside the five-name competitor set defined in Part 4. Show the gap. Show whether the gap is closing, holding, or widening month-over-month.
Block 4: Citation gap analysis
Most of these gaps close faster when you treat clinician author quotes as the AEO moat on the pages that need to win citation. List the prompts where one or more competitors are cited and the operator is not. For each gap, name the specific page that would need to win the citation, and the closest content asset already published.
The gap analysis is what turns the report from a status update into a content roadmap.
The four-block format takes about three hours to produce monthly if your AEO program is already producing the upstream content. It takes most agencies a full day if the content production side is also being scoped. The work is the work. The reporting is what gets the budget renewed.
How SoCal Sunrise generated 85 admissions and 2,297% ROI from SEO in 6 months
A ground-up SEO rebuild using the Pathfinder Parents Methodology turned an invisible online presence into a top-ranking admissions engine.
Read the case study →85 admits and 3,152 leads attributed to organic
Part 6. Common AEO measurement mistakes
The mistakes pattern across most behavioral health operators we audit. The list below is the one I run through whenever a client says their measurement stack is not telling them anything actionable.
Tracking too many prompts
The most common mistake. Tool gives you 500 prompt credits per month, so you track 500 prompts. The result is a citation share number that averages across modalities, locations, and insurance combinations and tells you nothing about where to spend your next content dollar.
Cut the set to the 25-50 prompts that actually map to admits.
Tracking the wrong prompts
Second most common. The marketer picks prompts based on what they think users type, not on what the keyword research shows users actually type. Build the prompt list from your real query data, not from a brainstorm.
Then add the multi-part compound prompts that the brand research surfaces.
Treating citation share as the only metric
If citation share goes up and admits do not, the program is producing visibility without producing the outcome the operator paid for. Citation share without attribution is a vendor metric.
The C-suite metric is citation share paired with admit attribution, paired with cost.
Assuming one engine’s pattern applies to all
ChatGPT cites differently from Perplexity, which cites differently from Claude, which cites differently from Google AI Overviews. The page structure that wins ChatGPT citations frequently does not win Perplexity citations.
The mistake is to build content for one engine and assume the others will follow. Read the citation patterns engine-by-engine.
Acting on month-one data
Month-one citation data is noisy. Engines update weights. Tool sampling varies. The temptation is to rewrite a page after one month of poor citation. Resist it. Read three months. Then act.
Part 7. Cost-per-citation and cost-per-admit benchmarks
$500-$1,500
Directional cost-per-citation range in the first six months of a mid-market BH AEO scope, before citation share compounds.
$200-$600
Directional cost-per-citation range in months seven through twelve as the same scope’s citation set expands.
$3,500-$7,000
Cost-per-admit floor most operators land at once AEO citations start converting to intake and admission volume.
15-25%
Citation share range Webserv treats as the first credible benchmark before the AEO program is considered load-bearing.
This is the section every CFO eventually asks for. The honest answer is the one the rest of the vendor market avoids: the benchmarks are still forming, in the same way the real cost of doorway-page programs only became visible after enough operators ran them long enough to measure, and any agency claiming firm cost-per-citation numbers in mid-2026 is either citing one client’s data or pretending.
The framing below is directional and ratio-based.
Cost-per-citation, directionally
Cost-per-citation is the operator’s monthly AEO investment divided by the count of cited prompts in the measurement set.
For a mid-market BH operator running a typical AEO scope, cost-per-citation in the first six months tends to land in the range of $80-$200 per cited prompt across the priority query set, with the number falling as the program matures and citation count grows on the same fixed investment.
Read that number two ways. As a standalone, it is roughly comparable to the cost of producing one strong piece of supporting content. As a trend, it should be moving down quarter-over-quarter.
If your cost-per-citation is rising past month six, your content investment is not converting into citation surface, and the program design needs a review.
Cost-per-admit, directionally
Cost-per-admit from AEO, especially when the citation strategy is paired with a behavioral health digital PR program, is the harder number and the one that defends the budget at the board level.
For operators with a clean attribution stack (the GA4 channel plus CRM tagging from Part 3), cost-per-admit attributable to AI citation traffic tends to compare favorably to paid search cost-per-admit in the same market, often landing in a range below the paid-search number but above the brand-direct number.
The ratio framing that holds across the operators we have measured: AI citation cost-per-admit lands in the same order of magnitude as local organic cost-per-admit, which is to say lower than paid media on a steady-state basis but with a longer ramp.
The point of the directional framing: do not put a specific dollar figure in your board report until you have six months of your own attribution data.
Use the directional logic to argue the case in months one through six, and switch to point estimates from your own data once you have the volume to defend them.
Part 8. The agency reporting standard
If you are paying an agency for AEO work, especially one that also runs healthcare PR and journalist outreach on your behalf, the monthly report should contain the four blocks from Part 5 at minimum.
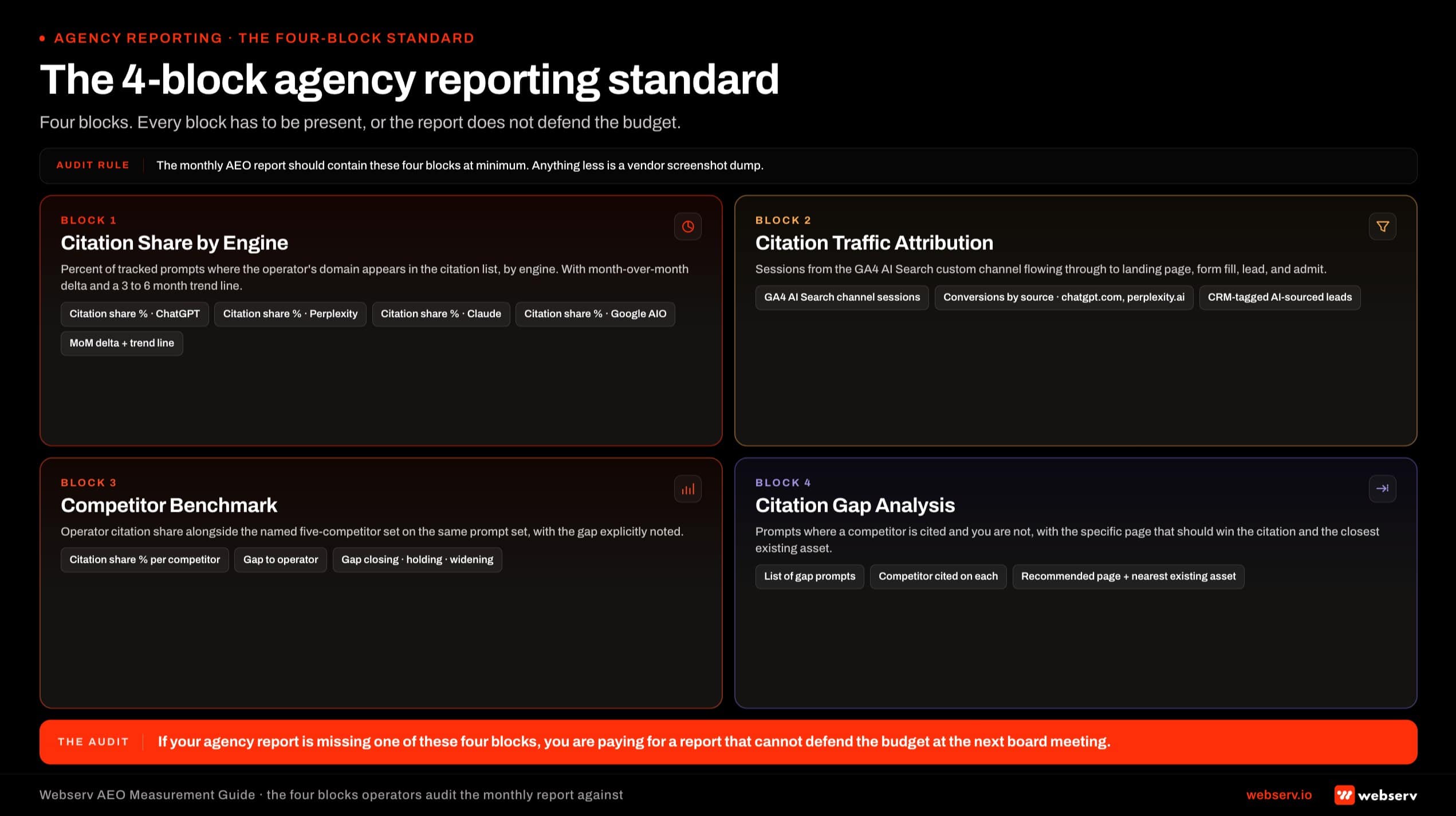
The checklist below is the one I would use if I were an operator evaluating whether the current report defends the budget or whether it is a vendor screenshot dump.
What an agency AEO report should include
One: citation share by engine, with month-over-month delta and three-to-six-month trend.
Two: citation traffic attribution from GA4, with AI-source sessions and conversions broken out.
Three: competitor citation share against the five-name set, with the gap explicitly noted.
Four: citation gap analysis, with named pages for each gap and the content move proposed.
Optional fifth block, recommended: a “what we are seeing” section that calls out engine-specific behavior changes month-over-month. AI engines update model weights weekly. Your agency partner should be reading those changes back to you so the program adjusts.
Red flags in an AEO report
Three red flags I look for when auditing an agency’s AEO reporting. First, screenshots of ChatGPT or Perplexity citations as the primary deliverable. Screenshots are receipts, not measurement.
Second, citation share without an attribution block. If the agency cannot tie citation share to traffic or leads, they have not done the GA4 setup work.
Third, the same prompt set every month without a refresh rationale. Operators evolve, modalities shift, and the prompt set should reflect that.
If you are evaluating an agency before signing, ask to see a sample monthly AEO report from an existing client. Our Top AEO agency listicle covers the agencies we benchmark against for this work.
Part 9. What changes monthly, quarterly, annually
AEO measurement runs on three cadence layers. Operators who treat all measurement work as a single cadence end up either over-reporting or under-acting. The split below is what we run for clients.
Monthly
Snapshot citation share. Pull GA4 attribution. Refresh the competitor benchmark. Produce the four-block report. Identify the top three citation gaps to address. Hand the gap list to the content production team.
Quarterly
Audit the prompt set. Are the 25-50 prompts still the right ones? Refresh based on new modality launches, insurance contract changes, and any patient acquisition strategy pivots. Audit the competitor set. Did a new competitor enter the citation field? Review the tool stack.
Is the current tool still right for the operator’s scale?
Annually
Re-baseline the measurement program. AI engines now in beta become primary citation surfaces. Tools consolidate or get acquired. The measurement stack a year ago is not the measurement stack today.
Build the annual program review into the budget cycle so the renewal conversation is about evolution, not a defense of stalled metrics.
Part 10. What changed in 2025 and 2026
Four shifts have changed AEO measurement since the work first emerged as a category.
One: Google AI Overviews rolled out as a default surface for many BH-relevant queries in late 2024 and through 2025, with Google’s I/O 2026 announcement of Gemini 3.5 Flash powering AI Mode globally extending the citation layer across virtually every informational search.
The blue-link click rate has compressed accordingly.
Two: ChatGPT Browse and the Perplexity citation strip moved from secondary surfaces in 2024 to primary citation patterns in 2025-2026. The tools listed in Part 2 of this guide did not exist in their current form 18 months ago.
Three: Tool market consolidation. AthenaHQ, Profound, and Peec AI all reached commercial product-market fit in late 2025. The category is still adding new entrants quarterly, and several of the 2024-era tools have either pivoted or been acquired.
Four: The position 2-5 reframe. The old SEO playbook treated positions 2-5 as a click-capture band. The new playbook treats them as the citation pool that AI Mode picks from. The work to get a page to position 2-5 is similar. The reason that work matters is different.
AEO measurement is the instrument that observes the reframe. Operators who pair the citation measurement work with strong digital PR earn the topical authority that compounds across both citation and ranking.
Where to start: a 90-day measurement build
If you are starting from zero, with the service-page funnel built before the blog layer, the build below gets you from no measurement stack to a defensible monthly report in 90 days.
Days 1-30: Set up the AI Search custom channel in GA4. Install the CRM tagging pattern (UTM or referrer capture). Define the 25-50 priority prompt set. Pick a tool from Part 2 sized to operator scale. Run the first baseline snapshot.
Days 31-60: Run the second monthly snapshot. Define the five-name competitor set. Begin the citation gap analysis. Start month-over-month tracking. Confirm GA4 channel data is flowing cleanly. Confirm CRM tagging is firing on AI-sourced leads.
Days 61-90: Run the third monthly snapshot. Produce the first full four-block report. Hand the citation gap list to the content production team. Present the report to the CMO with directional ratio framing on cost-per-citation and cost-per-admit. Set the cadence for the next quarter.
Past day 90, the program runs on the monthly-quarterly-annual cadence from Part 9. The instrument is built. The work becomes reading it correctly and acting on what it shows.
Frequently asked questions about AEO measurement for treatment centers
How long does it take to see meaningful AEO measurement data?
Ninety days is the floor for a credible C-suite report. Citation share moves monthly at the engine level, and the first two snapshots will look noisy because AI engines update model weights between runs. The signal stabilizes by month three.
Operators who try to act on month-one citation data typically make the wrong calls. A page that looks like it lost citation share in month one often recovers in month two as the engine reweights, and the rewrite the operator commissioned in week three was wasted. The three-month read prevents that pattern.
The honest answer most agencies will not give you: if your AEO program is less than 90 days old, your measurement output should be a baseline, not a verdict. The verdict comes at the end of month three, when you have three monthly snapshots and enough data to read direction.
Which AEO measurement tool should a single-location treatment center pick?
For a single-location operator with a marketing budget under $30K per month, the right starting point is either Peec AI at $100 per month or Otterly at $189 per month, depending on whether you need daily tracking on three engines or weekly tracking on four. Both are defensible first picks.
AthenaHQ at $295 per month makes sense the moment you cross two locations or your marketing budget passes $40K per month. The eight-engine coverage starts to matter when you are reporting to a board that asks about engines other than ChatGPT and Google AI Overviews.
Profound and BrightEdge do not make sense for single-location operators. The pricing is designed for portfolios, and the breadth of engines tracked is more than the operator can act on. Step into those tools only when you are running five or more locations or are inside a portfolio holding multiple facilities.
How many prompts should I track in my AEO measurement set?
25 to 50 prompts is the right starting range for almost every behavioral health operator. The prompts should map directly to the modalities, insurance combinations, and geographic anchors that produce admits, not to a brainstormed list of “things people might ask.”
The mistake to avoid is tracking 300 or 500 prompts because the tool gives you the credits. A 500-prompt set produces an averaged citation share number that moves slowly and tells you nothing about which specific service line is gaining or losing. Tighter prompt sets produce actionable signal.
Build the prompt list from your real query data (GSC top queries, paid search high-converting terms, CRM-tagged lead-source notes), then add the compound prompts that the brand research surfaces. Refresh the prompt set quarterly as the operator’s modalities and contracts shift.
How do I attribute AI citation traffic to admissions in my CRM?
Two patterns work. Pattern A uses a custom GA4 audience that flags AI-source sessions and fires a hidden form field with utm_source=ai-engine when the session converts. The CRM receives the UTM on the lead record. Pattern B captures the referrer URL at form submission into a hidden field, and the CRM stores the raw referrer.
Either pattern closes the loop from citation through to admit. Most BH CRMs already have a lead-source field; the work is making sure AI traffic populates it cleanly rather than falling into “Organic” by default. The setup is a one-time engineering task, not an ongoing reporting cost.
The compliance constraint matters. Do not pass health-condition keywords or PHI markers in UTM parameters or referrer strings. The HHS-OCR online tracking technologies bulletin makes IP-plus-health-info into PHI when captured by HIPAA-regulated entities, and AI attribution plumbing has to respect the same rules as paid-attribution plumbing.
What’s the difference between citation share and AI traffic?
Citation share measures how often AI engines cite your domain when responding to a defined set of prompts. AI traffic measures the sessions GA4 attributes to AI-engine referral domains. They are different numbers because not every cited user clicks through, and not every AI-referred session came from a citation your tracker measured.
The relationship between them is the part operators get wrong. Citation share can rise without AI traffic rising (the engines cite you more, but users read the answer without clicking). AI traffic can rise without citation share moving (more users follow the engines they already use without the engines citing you more often).
The right monthly report shows both. Citation share tells you whether the AEO content production work is landing. AI traffic tells you whether the citation work is producing site visits. Admit attribution tells you whether those visits convert. All three numbers matter; reporting only one of them produces an incomplete picture.
Should we measure all AI engines or focus on Google AI Overviews?
Measure four engines minimum: Google AI Overviews, ChatGPT, Perplexity, and Claude. Those four cover roughly 85 percent of AI search activity that matters to a US-based treatment center in 2026. Measuring fewer than four leaves blind spots; measuring more than eight rarely produces incremental signal worth the credit cost.
Google AI Overviews is the highest-impact single engine because it sits on top of standard Google search and captures the largest informational query volume. But focusing only on it is the same blue-link-era mistake of optimizing for one channel and missing the others.
The pattern that wins in 2026: measure the four-engine core monthly, snapshot Gemini and Meta AI quarterly, and add new engines as they reach the threshold of citation volume that matters. The threshold for “matters” is when a new engine’s referral traffic to your site crosses 2 percent of total AI-channel traffic.
A page that looks like it lost citation share in month one often recovers in month two as the engine reweights, and the rewrite the operator commissioned in week three was wasted. The three-month read prevents that pattern.
The honest answer most agencies will not give you: if your AEO program is less than 90 days old, your measurement output should be a baseline, not a verdict. The verdict comes at the end of month three, when you have three monthly snapshots and enough data to read direction.