Last Wednesday a treatment center operator we work with typed a question into ChatGPT: “what’s the best behavioral health marketing agency for a mid-size residential program in the Southwest?”
The model answered with three competitor names, a long paragraph about what to look for, and zero mention of his actual agency, his program, or any of the seven facilities the agency has helped scale over the last two years.
That gap, between what the operator knows about his facility and what AI knows about it, is the gap this article is about. Most treatment center owner-operators have heard about AI search, AI Overviews, ChatGPT citations, and “AEO.” Almost none have a clear answer for what to actually do.
On June 12, 2026 Google Cloud quietly published a spec that closes part of that gap. It is called the Open Knowledge Format, or OKF. Four days later, Webserv shipped the first OKF bundle in behavioral health marketing at webserv.io/okf/.
This piece is the operator-facing read on what OKF is, why we built one within a week, and the five-step playbook for treatment centers thinking about doing the same.
The full context for how AEO fits inside a behavioral health marketing program lives on our AEO capability page, but this article is the news read.
Key Takeaways
- The Open Knowledge Format (OKF) is an open spec Google Cloud announced on June 12, 2026 for representing organizational knowledge in a format AI agents can consume directly. It is markdown + YAML frontmatter, vendor-neutral, and lives in a public directory on your site.
- Webserv published the first OKF bundle in behavioral health marketing at webserv.io/okf/ on June 16, 2026: 28 typed concepts covering methodology, services, case studies, and benchmark data, served as plain markdown with the right content type. Built and shipped in roughly three hours.
- OKF is not a replacement for schema markup, llms.txt, an AI Information page, or an MCP server. It is the relational layer that sits on top of all of them. Other surfaces describe individual things; OKF describes how those things connect.
- Treatment centers can publish their own OKF bundle covering services, modalities, locations, alumni stories, and clinical leadership. Most existing site content can be ported with light editing rather than rewritten.
- No major AI engine has publicly committed to ingesting OKF yet. The format is days old. The case for publishing now is asymmetric: low effort to build, zero downside if adoption is slow, real upside if ingestion goes live in the next six to twelve months.
What Is the Open Knowledge Format?
The short version: OKF is a way to publish your facility’s structured knowledge in a format AI agents can read directly, without first scraping HTML or parsing schema.
The longer version. On June 12, Google Cloud announced OKF v0.1 on the Cloud blog, framing it as an open spec for representing organizational knowledge in a way AI tools can consume.
The format is markdown files plus YAML frontmatter, bundled in a directory of related concepts that cross-link with standard markdown links.
The conceptual ancestor of OKF is Andrej Karpathy’s LLM Wiki pattern, which proposed that organizations should maintain a public, AI-readable mirror of their internal knowledge.
Google Cloud’s contribution is the standard format. The frontmatter shape, the file structure, and the discovery convention are now spec rather than gist.
The format has four properties worth noting for operators. First, it is vendor-neutral. No SDK, no platform lock-in. Second, it lives in git or any filesystem and serves over plain HTTP.
Third, it is human-readable. A facility’s marketing director or clinical leader can open an OKF file and edit it directly. Fourth, it is composable with everything else in the AI search stack: schema markup, llms.txt, MCP servers, and AI Information pages all continue to play their roles.
The point of the spec is to give AI agents a canonical way to ask, “what does this organization actually know about its services, methodology, and outcomes?” The answer used to require crawling, parsing, and guessing. The answer now is a directory of typed concept files an agent can fetch.
How OKF Fits With the Rest of Your AI Search Surface
The question every operator asks within the first 90 seconds of hearing about OKF is, “isn’t this the same as the AI Information page you sold me last month?”
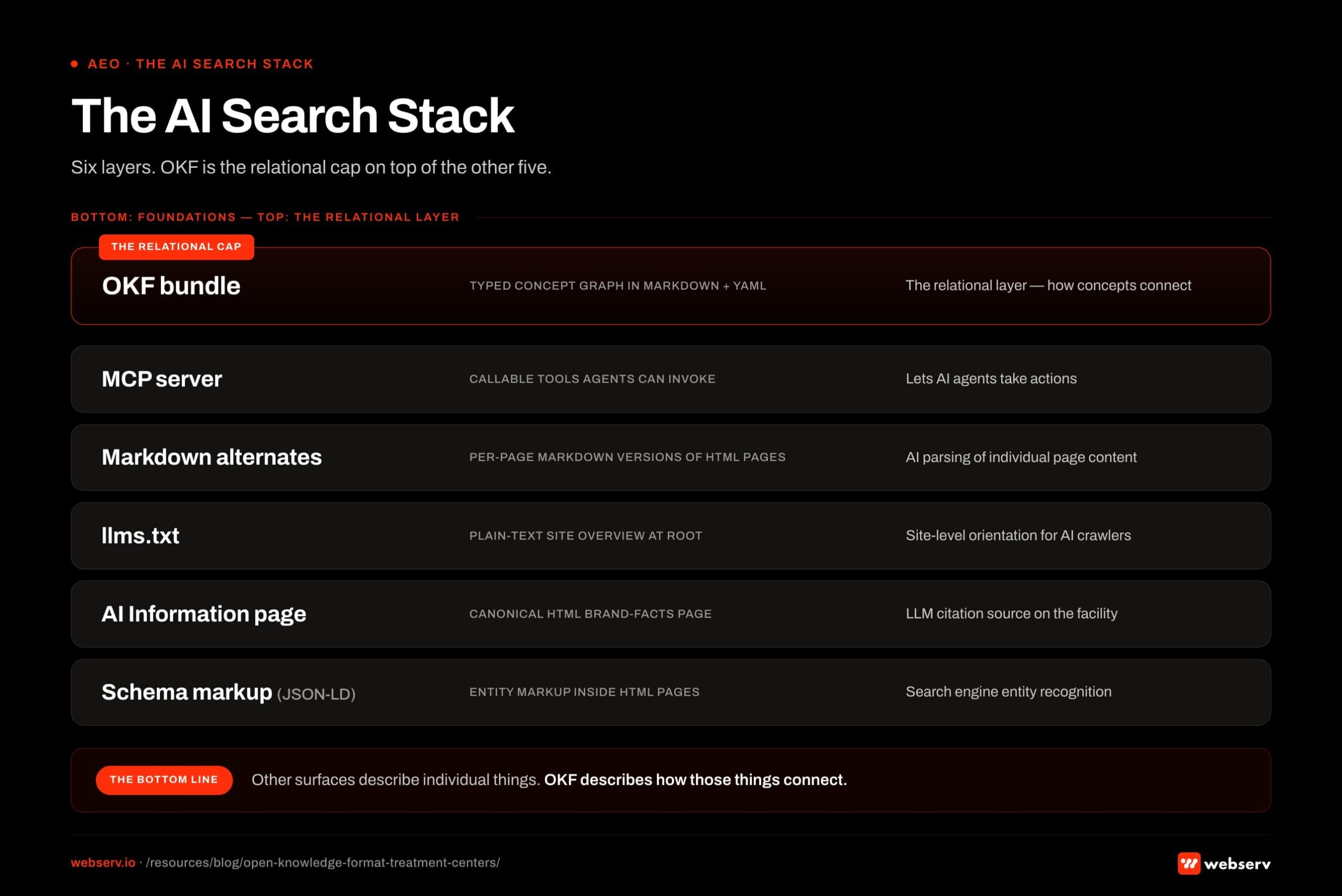 Six-layer AI search stack with Open Knowledge Format (OKF) capping the top. Bottom layer: schema markup. Above it: llms.txt. Above that: AI Information page. Above that: MCP server. Above that: cross-linked content cluster. Top: OKF, the compositional bundle that ties the layers together. OKF does not replace the lower layers; it composes them into a single referenceable resource for AI engines.
Six-layer AI search stack with Open Knowledge Format (OKF) capping the top. Bottom layer: schema markup. Above it: llms.txt. Above that: AI Information page. Above that: MCP server. Above that: cross-linked content cluster. Top: OKF, the compositional bundle that ties the layers together. OKF does not replace the lower layers; it composes them into a single referenceable resource for AI engines.It is not. The two surfaces solve different problems, and the full AI search stack has six layers that all work together.
| Surface | What it is | Best for |
|---|---|---|
| Schema markup (JSON-LD) | Entity markup inside HTML pages | Search engine entity recognition, rich results |
| AI Information page | A canonical HTML brand-facts page | LLM citation when the AI cites your facility |
| llms.txt | Plain-text site overview at root | Site-level orientation for AI crawlers |
| Markdown alternates | Per-page markdown versions of pages | AI parsing of individual page content |
| MCP server | Callable tools agents can invoke | Letting AI agents take actions on your behalf |
| OKF bundle | Typed concept graph in markdown + YAML | Letting AI agents understand the relationships between concepts |
OKF is the relational layer. Everything else describes individual things on your site. OKF describes how those things connect.
A service concept links to the case studies that prove it works, which link to the modalities that delivered the outcome, which link to the methodology behind the program. The graph is where the value compounds.
For most treatment centers, the right read on the stack is sequential. Schema markup and an AI Information page first. Then llms.txt and markdown alternates.
Then an MCP server if agentic search is part of the strategy. OKF sits at the end, after the others are in place, because it formalizes the relationships between things the other surfaces have already described.
The actual AI-readable knowledge graph took less time to ship than most facilities spend on a single blog post. The barrier is not technical effort. It is whether the operator decides to be the first OKF bundle in their category or the fortieth.
Preston Powell, CEO of Webserv
What Webserv Built (The Case Study)
We shipped the bundle on June 16, 2026, four days after Google’s announcement. The technical effort was small. The harder work was content. Here is what is live at webserv.io/okf/ today.
Twenty-eight concepts. One root index, one methodology page, nine services, eleven case studies, and two benchmark documents. Each concept is a separate markdown file with YAML frontmatter (type, title, description, resource, tags, timestamp) and a body.
Each file serves with Content-Type: text/markdown; charset=utf-8 and is discoverable via the existing /.well-known/api-catalog and the MCP server card we already had in place.
The 28 concepts cross-link to each other. The SEO service concept links to the case studies that delivered SEO outcomes. The Reconnect Center case study links to the services delivered and the methodology behind them.
The Predictable Patients methodology page links to every service that operationalizes the framework. The cross-links are where the graph value lives.
Build cost: roughly three hours. About 90 minutes of content authoring (mostly distilling existing service pages and case study writeups into the OKF concept shape) and 90 minutes building the small WordPress mu-plugin that serves the files with the correct content type and headers.
The actual AI-readable knowledge graph took less time to ship than most facilities spend on a single blog post.
The bundle is not a replacement for any of our other AI search surfaces. It sits alongside our AI Information page, our schema stack, our llms.txt, our MCP server, and the eight tools that server exposes. It is the relational map on top of everything else.
Why This Matters for AI Search Citations
AI search citations are the new top-of-funnel visibility metric for behavioral health, and the citation share game is shifting from “what does your page say?” to “what does your organization know?” That shift is the structural reason OKF matters.
When ChatGPT or Perplexity answers a treatment center query today, the answer is assembled from whatever the model could extract during crawling: schema markup, HTML page content, a few citation sources it has indexed. The relational structure (this service produces this outcome at this modality for this population) has to be inferred from prose.
OKF makes the relational structure explicit. An agent fetching a facility’s OKF bundle reads typed concepts with named relationships, not paragraphs that have to be parsed for meaning. The cost of answering a question correctly drops.
For behavioral health specifically, this matters more than for most categories. The healthcare YMYL frame already pushes AI engines toward institutional and credentialed sources at 30 percent of the citation mix per Profound’s 2026 analysis. The institutional-leaning citation pattern rewards facilities that publish structured, credentialed, machine-readable knowledge in formats AI engines trust.
The competitive dynamic is what makes the timing asymmetric. Fewer than 50 organizations across the entire web have shipped OKF bundles in the first week after the announcement. The first-mover window is real because the major AI engines tend to weight new formats more heavily during the initial adoption phase, before the format saturates.
Treatment centers that ship OKF bundles in the next 30 to 60 days position themselves to be among the first sources AI engines incorporate when ingestion goes live. Treatment centers that wait until ingestion is measurable miss the early-adopter weighting and publish into a saturated field.
Other AI search surfaces describe individual things. OKF describes how those things connect. That relational layer is where AI agents do their actual work, which is why the format will outlive the news cycle even if it takes another year for the major engines to fully ingest it.
Preston Powell, CEO of Webserv
The Treatment Center OKF Playbook
Five steps, sequenced over roughly a week of part-time effort. The playbook works for a single-facility operator with an in-house marketing director and a developer or agency partner who can handle the serving piece.
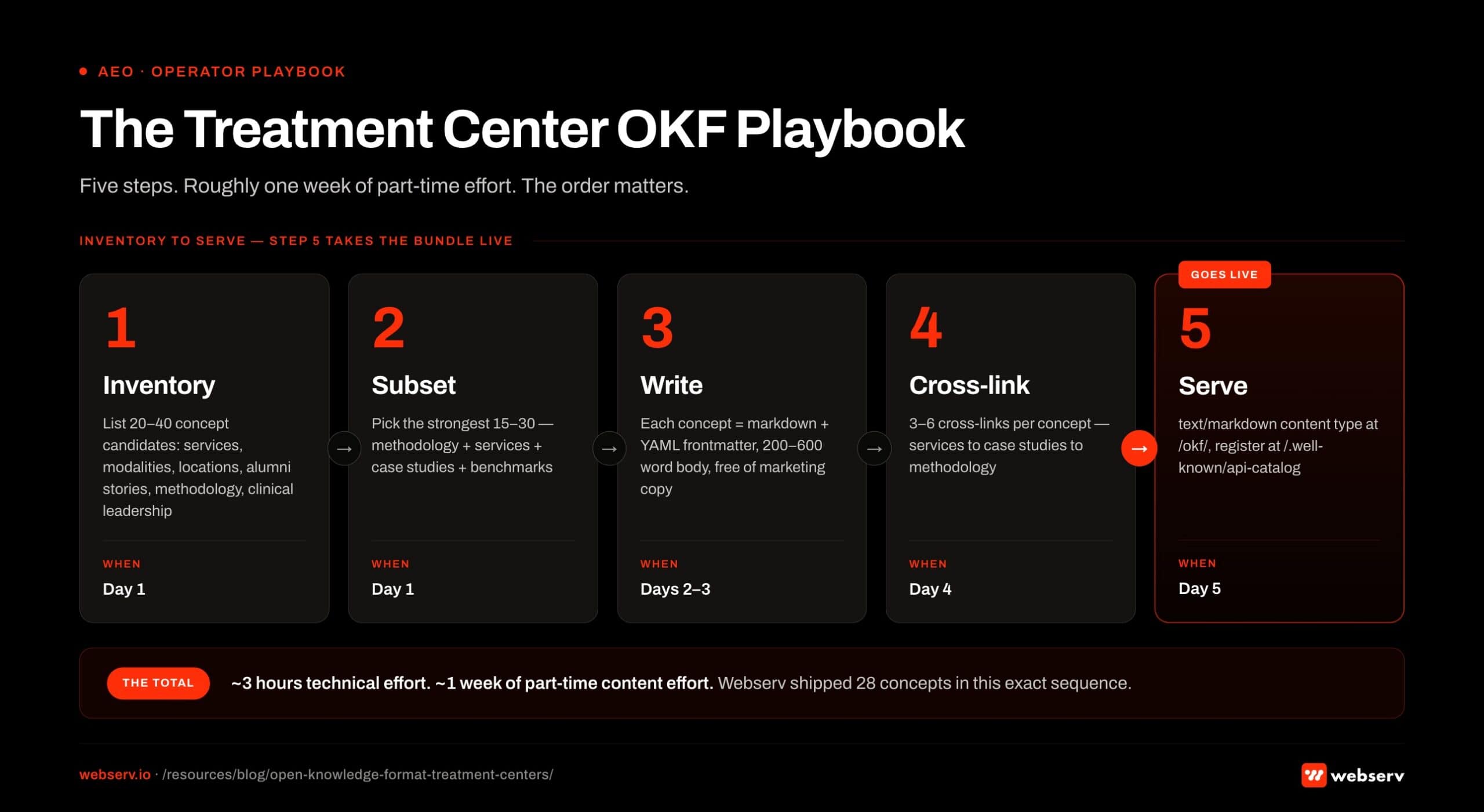 Five-step treatment center OKF playbook executed over roughly a week of part-time effort. Step 1 inventory: list the 25-30 core concepts your treatment center should own in AI search. Step 2 subset: identify which existing pages already cover each concept. Step 3 write: draft OKF entries for any concepts without existing canonical content. Step 4 cross-link: connect each entry to 3-6 supporting URLs in the corpus. Step 5 serve: ship the JSON bundle at a stable URL and confirm AI engine ingestion.
Five-step treatment center OKF playbook executed over roughly a week of part-time effort. Step 1 inventory: list the 25-30 core concepts your treatment center should own in AI search. Step 2 subset: identify which existing pages already cover each concept. Step 3 write: draft OKF entries for any concepts without existing canonical content. Step 4 cross-link: connect each entry to 3-6 supporting URLs in the corpus. Step 5 serve: ship the JSON bundle at a stable URL and confirm AI engine ingestion.Step 1: Inventory your knowledge. (Day 1.) List the concept types that matter for your facility: services (detox, PHP, IOP, residential, sober living, MAT), modalities (CBT, DBT, EMDR, trauma-informed care, family therapy), locations, alumni stories or case studies, named clinical leadership, methodology or treatment philosophy, accreditations, and any benchmark or outcome data you can publish without violating compliance.
The output of Step 1 is a flat list of 20 to 40 concept candidates. Most treatment centers find they already have the source material for each concept somewhere on the site or in internal docs.
Step 2: Subset to the bundle scope. (Day 1.) Pick the 15 to 30 concepts that form the strongest initial bundle. The right shape is anchored by a methodology document, then services, then case studies that prove the services work, then a few benchmark or context documents.
Resist the urge to publish everything at once. A tight 20-concept bundle that cross-links well outperforms a 60-concept bundle with weak relationships. Start tight and expand later.
Step 3: Write each concept. (Days 2 to 3.) Each concept is a separate markdown file with YAML frontmatter (type, title, description, resource URL, tags, timestamp) and a body of 200 to 600 words.
The body should be tight, factual, and free of marketing copy. AI engines extract better signal from direct prose than from promotional language. A clinician can write a clinical concept file in 15 to 30 minutes.
Step 4: Cross-link the concepts. (Day 4.) The graph value compounds in the cross-links. A service concept should link to the case studies that delivered outcomes from that service. A case study should link back to the services involved and the methodology behind them. A methodology document should link to every service that operationalizes the framework.
The right density is 3 to 6 cross-links per concept. Below that, the graph is too thin to compound; above that, the relationships get noisy.
Step 5: Serve the bundle. (Day 5.) The technical layer: serve each file with Content-Type: text/markdown; charset=utf-8, expose the bundle root at /okf/, and register the discovery convention at /.well-known/api-catalog. For WordPress, a small mu-plugin handles the content type and rewrite rules in under 90 minutes of dev work.
For non-WordPress sites (Webflow, custom platforms, static site generators), the implementation varies but the pattern is the same: serve markdown with the right header at a predictable path. Most engineering teams can complete the serving piece in an afternoon.
How to Know If You’re Ready
OKF is most valuable when the foundational AI search surfaces are already in place. Five readiness signals tell operators whether to ship OKF this month or to fix the prerequisites first.
- Clean schema.org Organization and MedicalBusiness markup deployed sitewide.
- A canonical AI Information page (the brand-facts page LLMs cite from).
- A current llms.txt at the root of your site.
- Reasonable site speed, with Core Web Vitals passing on mobile.
- Author and reviewer bios for the clinicians who appear on your YMYL content.
Treatment centers that have all five in place can ship an OKF bundle this month with high confidence. Treatment centers missing two or three prerequisites should fix those first, since OKF amplifies the credibility signal of what is already on the site rather than creating it from scratch.
The authority content layer covers the bio and reviewer infrastructure that pairs with the OKF bundle, and the broader SEO program handles the schema and technical work.
For operators below the readiness threshold, the right sequence is foundational AI surface work first (typically 30 to 60 days), then OKF. For operators already at the readiness threshold, ship this month before the first-mover window closes.
Frequently Asked Questions
Do I need a developer to publish an OKF bundle?
Light developer help is useful but not strictly required. The content itself is plain markdown with YAML frontmatter that any marketing director or clinical leader can write directly. A clinician can open an OKF concept file and edit it without learning a new tool.
The technical piece is serving the files with the correct content type (text/markdown; charset=utf-8) and registering them in the standard discovery convention. For WordPress sites, this is a small mu-plugin or a server-level rewrite rule. The Webserv bundle’s plugin took roughly 90 minutes to build.
Most multi-facility operators have either an internal developer who can handle the serving piece or an agency partner who can. The content authoring is the bigger time commitment, and that work is operator-led.
Will publishing OKF affect my Google rankings?
Not directly. OKF is not a Google ranking signal as of June 2026. Google Cloud announced the format as an open spec, not as a search ranking input, and Google Search has not committed to ingesting OKF bundles for organic ranking purposes.
The indirect effect is that AI search citations (ChatGPT, Perplexity, Claude, Gemini, Google AI Overviews) increasingly feed back into the broader visibility and brand-signal layer that does influence organic ranking over 12 to 24 month cycles. If OKF ingestion lands at any major AI engine, citation share lifts, which lifts the topical authority that organic ranking already rewards.
The bet is asymmetric: publishing now costs roughly three hours, and the downside if adoption is slow is zero. The upside if ingestion goes live in the next six to twelve months is meaningful AI citation share lift for first movers.
Does OKF replace my schema markup?
No. Schema markup and OKF solve different problems. Schema markup (JSON-LD) is entity markup inside your HTML pages, used by search engines for entity recognition and rich results. OKF is a separate bundle of typed concept files in markdown, used by AI agents for relational understanding of how concepts on your site connect.
The right read is sequential. Schema markup goes first because it serves the much larger organic search and AI Overview surfaces today. AI Information page, llms.txt, and markdown alternates of key pages come next. OKF sits at the end of the stack as the relational layer that formalizes connections between concepts the other surfaces already describe.
Treatment centers without strong schema markup should fix that first. OKF is an additive surface, not a replacement for the foundational entity work.
What’s the difference between OKF and llms.txt?
llms.txt is a single plain-text file at the root of a site that gives AI crawlers a site-level overview: what the site is, what the primary pages are, and where to find canonical content. It is one file, flat, and descriptive.
OKF is a directory of typed concept files that cross-link to each other to form a knowledge graph. Each concept (a service, a case study, a methodology, a benchmark) is its own markdown file with structured frontmatter, and the relationships between concepts are first-class data.
llms.txt answers “what is this site about?” in 200 words. OKF answers “how do this organization’s services, outcomes, methodology, and clinical work connect?” across dozens of structured files. Treatment centers should publish both. They complement each other.
How do I know if ChatGPT or Claude is reading my OKF bundle?
As of June 2026, the major AI engines have not announced OKF ingestion publicly. The detection signal is not yet a server log entry tagged as “ChatGPT-OKF-Reader.” That visibility will come later as ingestion goes live and crawlers identify themselves.
What treatment centers can measure today is the indirect signal: AI citation share on representative prompts before and after publishing the OKF bundle. Most operators we work with use a monthly manual sampling protocol against 15 to 20 representative behavioral health prompts plus a citation-tracking tool subscription.
The honest framing is that this is a first-mover bet. The measurable lift will show up in citation share over 6 to 12 months as engines incorporate OKF data into their answer generation. Publishing now positions the facility for that lift; waiting until lift is measurable means publishing after every competitor has done the same.
How do I keep an OKF bundle up to date when my site content changes?
The cleanest pattern is to treat OKF concepts as canonical and have HTML pages reference them, rather than maintaining two parallel content systems. When a service page changes, the OKF concept for that service gets updated as part of the same workflow.
For most treatment centers, the practical setup is a quarterly OKF review cadence aligned with the editorial calendar. Once per quarter, the team reviews each concept file, updates any data that has shifted (case study metrics, modality offerings, clinical staff), and pushes the changes to the bundle.
The maintenance overhead is small relative to the initial build. The concepts that change most often (case studies with new outcome data, services with new modalities) get more frequent updates. The stable concepts (methodology, leadership bios) often go a full year between edits.
The First-Mover Window Is Open: Here’s How to Move
The Open Knowledge Format is four days old as of this article’s publish date. Fewer than 50 organizations across the web have shipped bundles. Behavioral health, as far as we can tell, has one: webserv.io/okf/.
The competitive math is asymmetric in a way that rarely shows up in marketing decisions. Roughly three hours of effort for a bundle that may produce zero return if AI engine adoption stalls. Roughly three hours of effort for a bundle that may produce meaningful AI citation share lift if adoption goes live in the next six to twelve months. The downside is bounded; the upside is not.
We help treatment centers ship OKF bundles paired with the broader AEO program: schema infrastructure, AI Information page, llms.txt, markdown alternates, MCP server, and the credentialed authorship work that earns AI citation share over 12 to 24 months. The OKF bundle is one component of the stack; the program is what produces the compounding return.
Book an intro meeting to see what an OKF bundle would look like for your facility, where the readiness gaps are, and how the bundle pairs with the broader AI search program. The first-mover window is open now; it will not be open in six months.
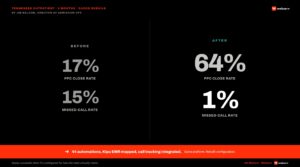
For operators thinking about the broader investment frame, our rehab patient acquisition playbook and the 2025 state of rehab marketing benchmarks cover the context the AEO work lives inside. The Reconnect Center case study shows what the full program produces over 6 weeks: 21 AI Overview citations on behavioral health queries.
Trevor Gage is the Director of Earned and Owned Media at Webserv, where he leads SEO, AEO, and digital PR for behavioral health and addiction treatment centers across the U.S. He writes about the cross-platform visibility work that earns treatment centers citation share in AI search alongside organic rankings and earned media coverage.