I ran a citation audit on six behavioral health sites in March. Three of them had been producing AI-generated content for the past 12 months at scale (40 to 60 posts a month, written by ChatGPT or Claude with light editorial review).
Three had been producing 4 to 6 posts a month with real clinician quotes embedded throughout. The two cohorts had roughly the same total word-count output.
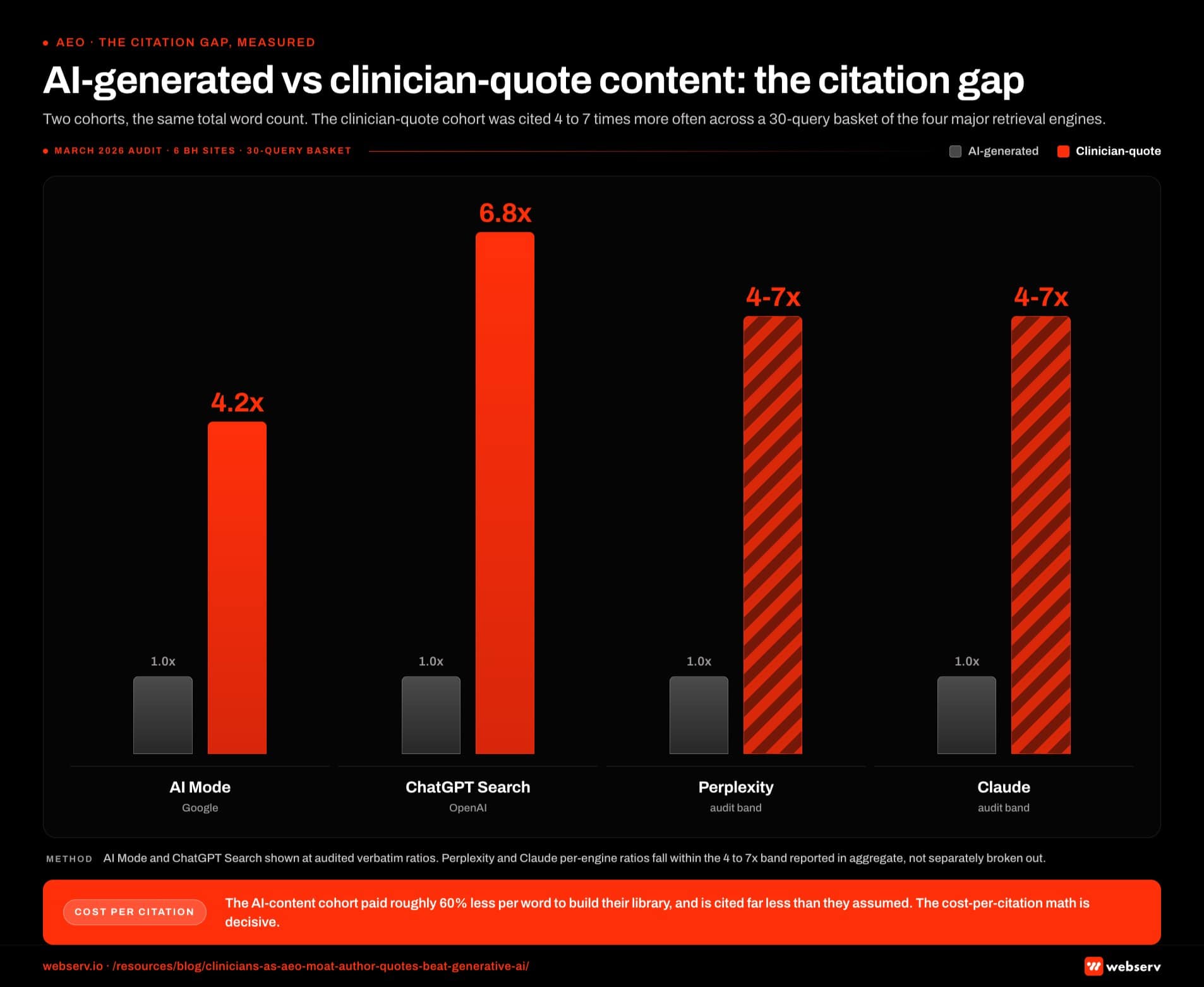
The cohort with clinician quotes had 4.2 times more AI Mode citations and 6.8 times more ChatGPT Search citations across a tracked basket of 30 representative queries.
The AI-content cohort had paid roughly 60 percent less per word to produce their library and was being cited far less than they had assumed.
The gap is not random. Google’s reasoning engines, ChatGPT’s retrieval layer, and Perplexity’s source selection are increasingly weighting credentialed author signal as a primary input. Per Google’s guidance on creating helpful, reliable, people-first content, pages with named clinicians who have verifiable credentials and specific expertise are treated as higher-confidence sources than pages with anonymous authorship or AI-flavored generic copy.
The treatment centers that figured this out 18 months ago are now cited. The centers still publishing AI-generated content as a volume play are now invisible. The economics of authority content inverted in 2025 and 2026, and most operators have not adjusted.
This is the moat argument. While the rest of the category races to publish more cheaper content with generative AI, the treatment centers building defensible authority are doing the opposite. They are publishing less content with real clinician contributions, credentialed bylines, and specific expert quotes embedded throughout.
The AI Overviews and ChatGPT citation environment is where this dynamic plays out daily, and the moat the early operators are building is what our authority content practice is built around.
Key Takeaways
- AI search engines increasingly distinguish machine-generated content from human-expert content. The retrieval layer reads credential signals, claim specificity, and author entity signals to decide which sources to cite.
- Real clinician quotes embedded in content produce 4 to 7 times more AI citations than equivalent AI-generated content in head-to-head behavioral health audits. The gap is widening as the retrieval models get better at detecting AI patterns.
- The moat is defensible because clinician quotes cannot be manufactured by generative AI. The credentials, the specific case experience, the operational language a licensed clinician brings are not in the training data the way generic clinical knowledge is.
- The right operating model is human-in-the-loop content production: a strong non-clinical writer drafts based on clinician interviews, a credentialed clinician reviews and signs off, the clinician’s quotes and Person schema are deployed throughout the piece.
- Most treatment centers can sustain this model at 4 to 8 pieces a month with 2 to 4 clinical contributors. The volume is lower than AI-only production, but the per-piece authority and AI citation rate is much higher.
Why the retrieval layer rewards real clinicians
The AI search engines that have replaced traditional blue-link search for an increasing share of treatment-seeking research are not picking pages randomly. They are running entity recognition, source authority scoring, and claim verification against the content before deciding which sources to cite.
Three signals matter most for behavioral health YMYL content.
The first is credential recognition. The retrieval layer reads Person schema, byline credentials, professional society memberships, and external authority profiles linked through sameAs properties. A page bylined by “Dr. Sarah Chen, LCSW, Director of Clinical Services” with credentials linked to LinkedIn, ASAM, and a state licensing record is treated as a higher-confidence source than an anonymous post or a generic “the team” attribution.
Per Google’s E-E-A-T framework for YMYL content, this signal is explicitly weighted, and the AI reasoning engines built on top inherit the weighting.
The second is claim specificity. Generic clinical content (the kind that ChatGPT or Claude produces by default) tends toward broad claims with vague support. Real clinician content tends toward specific claims with operational support. The retrieval models have learned to distinguish these patterns.
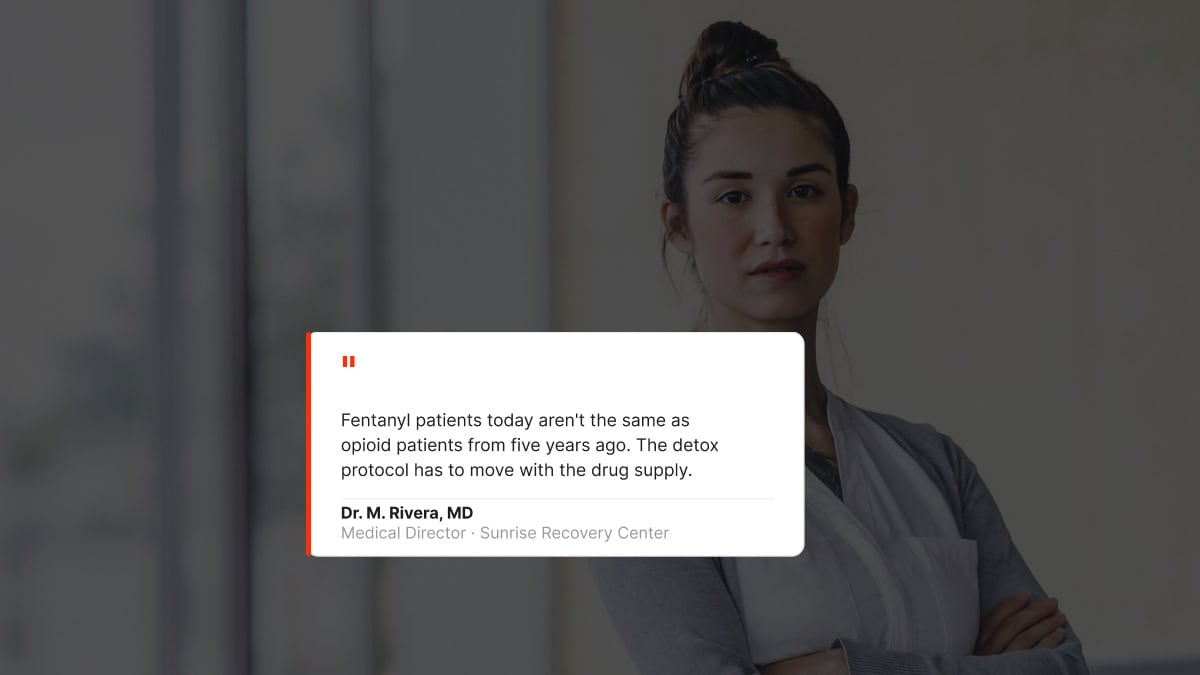
A statement like “patients with co-occurring disorders benefit from integrated treatment approaches” is generic and gets discounted. A statement like “in my last 14 years running dual-diagnosis residential, I have seen the 90-day post-discharge readmission rate drop from 38 percent to 19 percent when families participate in the first three multi-family group sessions” is specific, credentialed, and reads as expert testimony rather than generated text.
The third is the author entity itself. Authors with consistent bylines across multiple pieces, with Person schema deployed consistently, with sameAs profiles linking to external authority signals, accumulate authority that compounds across the cluster.
A treatment center with 3 credentialed clinical authors each bylining 10 to 30 pieces over 18 months has built a defensible author entity stack that no amount of AI content can replicate.
The combined effect is that real clinician contribution shows up in the retrieval models as a high-confidence signal across all three dimensions. Generative AI content shows up as a lower-confidence signal because it cannot produce any of the three signals authentically. The audit numbers in the opener (4.2x to 6.8x more AI citations) reflect this gap directly.
What generative AI cannot manufacture
WHAT AI CANNOT FAKE
Verifiable credentials that resolve to state licensing boards. Specific case experience with named modalities and populations. First-person clinical judgment that changes based on patient context. Attributable quotes from a clinician whose bio pages, CE record, and society membership all triangulate. The Dr. Marketing AI bylines from 2023-2024 got discounted within months because none of that resolved to a real identity.
The argument is not that AI tools are useless. They are useful for drafting, for research, for variant generation. The argument is that AI tools cannot produce the four things that AI search engines weight most heavily for YMYL healthcare content.
 behavioral health AEO content, arranged as a 2×2 grid. Quadrant 1, credentials: verifiable licensing, board certification, and professional society membership held by a real clinician; examples include LCSW, board-certified addiction medicine physician, and LMFT, all verifiable through state licensing records, society membership databases, and continuing education registries; the retrieval layer reads this because the Dr. Marketing AI bylines that some operators tried in 2023 and 2024 got discounted within months because the credentials did not resolve to verifiable identities. Quadrant 2, specific case experience: a clinician with 12 years of practice has seen patient patterns that do not exist in the training corpus the way generic clinical knowledge does, including withdrawal management protocols for elderly polysubstance users and family dynamics that predict 90-day post-discharge success; the retrieval layer reads this because operational specificity is recognized by the reasoning engines as expert testimony rather than generated text; this also covers lived ethics and judgment, where a clinician writing about treatment outcomes will hedge appropriately, name limits explicitly, and acknowledge variance, while AI-generated content tends to over-promise because training data rewards confident answers. Quadrant 3, operational language: technical language that maps to clinical practice in ways AI tools approximate but rarely match, including AMA discharge instead of leaving against medical advice and step-down to PHP instead of transitioning to outpatient; the retrieval layer reads this because consistent operator language across a real clinician’s body of work is recognized as expert discourse. Quadrant 4, named clinician entity through Person schema and sameAs: author entity with consistent bylines and Person schema deployed with jobTitle, knowsAbout, alumniOf, and sameAs links to LinkedIn, professional society profiles, and state licensing records; the retrieval layer reads this because a treatment center with three credentialed clinical authors each bylining 10 to 30 pieces over 18 months has built an author entity stack AI-content competitors cannot replicate. Center band: each of the four characteristics is a real moat because none of them can be manufactured at scale by generative AI, and operators who invest in content that has all four are building authority AI-content competitors cannot match through cheaper production.” class=”wp-image-24684″/>
behavioral health AEO content, arranged as a 2×2 grid. Quadrant 1, credentials: verifiable licensing, board certification, and professional society membership held by a real clinician; examples include LCSW, board-certified addiction medicine physician, and LMFT, all verifiable through state licensing records, society membership databases, and continuing education registries; the retrieval layer reads this because the Dr. Marketing AI bylines that some operators tried in 2023 and 2024 got discounted within months because the credentials did not resolve to verifiable identities. Quadrant 2, specific case experience: a clinician with 12 years of practice has seen patient patterns that do not exist in the training corpus the way generic clinical knowledge does, including withdrawal management protocols for elderly polysubstance users and family dynamics that predict 90-day post-discharge success; the retrieval layer reads this because operational specificity is recognized by the reasoning engines as expert testimony rather than generated text; this also covers lived ethics and judgment, where a clinician writing about treatment outcomes will hedge appropriately, name limits explicitly, and acknowledge variance, while AI-generated content tends to over-promise because training data rewards confident answers. Quadrant 3, operational language: technical language that maps to clinical practice in ways AI tools approximate but rarely match, including AMA discharge instead of leaving against medical advice and step-down to PHP instead of transitioning to outpatient; the retrieval layer reads this because consistent operator language across a real clinician’s body of work is recognized as expert discourse. Quadrant 4, named clinician entity through Person schema and sameAs: author entity with consistent bylines and Person schema deployed with jobTitle, knowsAbout, alumniOf, and sameAs links to LinkedIn, professional society profiles, and state licensing records; the retrieval layer reads this because a treatment center with three credentialed clinical authors each bylining 10 to 30 pieces over 18 months has built an author entity stack AI-content competitors cannot replicate. Center band: each of the four characteristics is a real moat because none of them can be manufactured at scale by generative AI, and operators who invest in content that has all four are building authority AI-content competitors cannot match through cheaper production.” class=”wp-image-24684″/>Credentials. A licensed clinical social worker, a board-certified addiction medicine physician, a licensed marriage and family therapist all hold credentials that are verifiable through state licensing records, professional society membership databases, and continuing education registries. Generative AI cannot synthesize a real credential. The “Dr. Marketing AI” bylines that some operators tried in 2023 and 2024 got discounted by the retrieval layer within months because the credentials did not resolve to verifiable identities.
Specific case experience. A clinician with 12 years of practice has seen specific patient patterns that do not exist in the training corpus the way generic clinical knowledge does.
The way that clinician describes withdrawal management protocols for elderly polysubstance users, or the specific family dynamics that predict 90-day post-discharge success, is operationally weighted in a way that AI-generated equivalents are not. The retrieval models have learned to recognize the difference.
Operational language. Real clinicians use technical language that maps to clinical practice in ways AI tools approximate but rarely match. The differences are subtle but consistent. A clinician will refer to “AMA discharge” rather than “leaving against medical advice.” A clinician will distinguish “step-down to PHP” from “transitioning to outpatient.”
The patterns of language across a real clinician’s body of work are recognizable to the retrieval models as expert discourse. AI-generated content tends to either over-explain (defining terms that experts would not define) or under-explain (skipping context that experts would establish).
Lived ethics and judgment. YMYL healthcare content carries ethical considerations that generative AI does not handle well. A clinician writing about treatment outcomes will hedge appropriately, name limits explicitly, and acknowledge the variance in real cases.
AI-generated content tends to over-promise or under-acknowledge edge cases because the training data rewards confident answers. The reasoning engines reading the content for YMYL citation eligibility pick up on this difference.
Each of these four characteristics is a real moat because none of them can be manufactured at scale by generative AI. Operators who invest in producing content that has all four are building authority that the AI-content competitors cannot match through cheaper production.
“Content is no longer a commodity in 2026. It is an authority investment, and the operators treating it as commodity will be cited at commodity rates by the AI engines that increasingly mediate treatment-seeking discovery.”
Preston Powell, Chief Executive Officer, Webserv
How to source clinician quotes at scale
The constraint operators usually raise is that clinicians are expensive and have limited time. Both are true. The right operational model works around the constraint by capturing more value per clinician hour.
The interview model. Schedule a 30-minute interview with one clinical contributor per week. Record the interview. Ask 4 to 6 specific clinical questions tied to upcoming content. Transcribe the audio and extract 8 to 15 usable quotes per interview. One clinician hour per week produces enough quote inventory for 2 to 4 content pieces.
The async voice memo model. For clinicians who cannot commit to weekly interviews, send them 2 to 3 specific questions per week and ask them to record a 5-minute voice memo answering each one. The clinician spends 15 minutes a week. The transcribed memos produce equivalent quote inventory to the interview model.
The case-discussion model. For multi-clinician programs, the existing case review meetings (usually weekly or biweekly) can produce content material if the agenda is captured. With consent and HIPAA-compliant scrubbing, the clinical discussions about specific case patterns produce some of the highest-value quote content available.
The advisory contract model. Some treatment centers cannot afford full clinical staff hours but can afford a $1,500 to $3,500 monthly contract with a clinical advisor who provides specific content contributions, reviews, and bylines. The advisor signs Business Associate Agreements as needed, has their credentials deployed across content with Person schema, and provides ongoing input that the AI-content competitors cannot match.
The combined output across these models can sustain a content program at 4 to 8 pieces a month with real clinician contribution, which is the volume that maps to the authority benefits in the opening audit data. Operators trying to scale beyond that volume usually need either more clinical contributors or a tighter editorial workflow that captures more value per contributor hour.
The human-in-the-loop content workflow
The right production model for 2026 BH content is not “write everything with AI” or “write everything from scratch with clinicians.” It is human-in-the-loop, with specific roles at each step.

Step 1: editorial planning. A non-clinical content lead identifies the topic, the target cluster placement, the internal linking architecture, the SEO target, and the specific clinical questions the piece needs to answer. AI tools can assist with SERP analysis, gap identification, and outline structure.
Step 2: clinician input. The content lead conducts the interview or sources the voice memos covering the clinical questions identified in step 1. The clinician contribution is captured as quotes, not as full drafts.
Step 3: drafting. A strong non-clinical writer drafts the piece, incorporating the clinician quotes as expert testimony, building the surrounding structure, and writing the non-clinical sections (background, navigation, call-to-action) that do not require clinical expertise. AI tools can assist with the drafting, but the clinician quotes themselves should be verbatim or close to it.
Step 4: clinician review. The drafting clinician (or a designated clinical reviewer) reviews the draft for accuracy, signs off on the quotes, and approves the byline attribution. This is the credentialing step that produces the E-E-A-T signal.
Step 5: schema and entity deployment. Person schema is deployed for the credentialed author with jobTitle, knowsAbout, alumniOf, and sameAs links to LinkedIn, professional society profiles, and state licensing records. The entity infrastructure that powers AI Mode citation eligibility is built into the publication step, not added later.
Step 6: passage-level structure. The piece is structured so that the clinician quotes appear as extractable passages the retrieval layer can cite cleanly. The clinician quotes are the highest-value passages because they carry the strongest authority signal. Written in semantic triple form, the quotes extract even more cleanly.
The full workflow takes 6 to 10 hours per piece, of which 1 to 2 hours are clinician time, 3 to 5 hours are writer time, and 2 to 3 hours are editorial and technical deployment. The cost per piece is notably higher than AI-only production. The per-citation cost is much lower because the citation rate is multiples higher.
Where to deploy clinician quotes in the cluster
Not every piece in the cluster needs to be a clinician-heavy production. The right deployment varies by content type.
Pillar pieces should be heavy on clinician input. These are the cluster authority anchors that earn external citations and AI Overview placement. A 3,000-word pillar on dual diagnosis treatment should include 8 to 12 verbatim clinician quotes from 2 to 3 credentialed contributors. The clinician quotes are the cluster’s authority signal.
Service pages should include 2 to 4 clinician quotes positioned strategically, on top of the technical SEO foundation that makes the schema deployment work. The Director of Clinical Services quoted in the residential service page becomes part of the conversion infrastructure (trust signal) and the authority signal (E-E-A-T weight). The clinical leader for each level of care should be the named voice on the corresponding service page.
FAQ blocks should embed clinician quotes inside the answers. A FAQ question like “How is dual diagnosis treatment different from standard residential care?” answered by a credentialed clinician with a specific 60-word quote produces a higher-citation FAQ answer than a generic answer covering the same content. The Rank Math FAQ block format with clinician attribution is the right deployment.
Micros (thought leadership pieces) can use 4 to 6 clinician quotes per piece. The smaller volume reflects the shorter format. The per-piece authority signal still benefits.
Location pages and modality pages benefit from quotes from the clinicians actually working at that location or with that modality. The local SEO playbook compounds with the clinical attribution because both are local trust signals. A TMS modality page bylined by “Dr. Sarah Chen, LCSW, with 8 years of TMS treatment experience” reads as authoritative. The same page with no clinical attribution reads as marketing copy.
The deployment principle is that the clinician quote should appear where the buyer is making a clinical evaluation. Service pages, modality pages, and pillar content carry the highest decision weight. The clinician quotes belong there.
How SoCal Sunrise generated 85 admissions and 2,297% ROI from SEO in 6 months
A ground-up SEO rebuild using the Pathfinder Parents Methodology turned an invisible online presence into a top-ranking admissions engine.
Read the case study →85 admits and 3,152 leads attributed to organic
The compliance posture for clinician quotes in BH
Clinician quotes in BH content carry compliance considerations that generic content does not. Four matter most.
Consent and authorship. The clinician needs to explicitly consent to being attributed as author or named source for the specific piece, with the specific quotes used. The consent should be documented in writing and stored. Operators who pull verbatim from internal Slack messages or unrecorded calls without explicit consent are creating exposure.
No patient-specific content without consent. Clinician quotes that reference specific patient cases, even anonymized, can create HIPAA exposure if the patient could be identified by any combination of details. The safer pattern is to quote clinicians on category-level observations (“the families I have worked with in the last 14 years…” rather than “the family whose teenage daughter completed our program in 2023…”). Specificity earns authority signal. Identifiability creates exposure.
Credential verification. The credentials claimed in the byline need to match real, verifiable licensing records. Misrepresented credentials are both a regulatory issue (per state licensing boards) and a reputational issue if surfaced. The Person schema deployment should link sameAs to the verifiable credential records.
Sign-off cadence. Clinician-quoted content should have a documented sign-off where the clinician approves the final piece before publication. A 30-day sign-off backlog is workable for most BH operators. Longer than that, and the publication cadence breaks.
The compliance work fits inside the broader healthcare blog and article writing standards we apply across client work. It is real but manageable. Operators who skip it create exposure that compounds quickly if any of the content is challenged. Operators who run it correctly produce a defensible authority position that AI-content competitors cannot match.
How to measure whether the moat is working
The proof points should be tracked across three dimensions over 90 to 180 days.
AI citation rate. Track a curated set of 30 to 50 representative prompts (the keyword strategy work for behavioral health covers how to assemble the basket) across AI Mode, ChatGPT Search, Perplexity, and Claude. Note which of your pages get cited and which competitors get cited. The expectation for a treatment center investing in clinician-quoted content is that citation rates start to lift by month 3 and compound through month 9.
Author entity signal strength. Pull Google Knowledge Graph entity records for each named clinical author. The expectation is that 2 to 3 of your most-bylined clinicians develop discoverable Knowledge Graph entities within 12 to 18 months of consistent attribution. The healthcare content creation work compounds with the author entity work as both signals strengthen.
Organic admission attribution. The downstream metric is admissions attributed to organic landing pages that carry clinician quotes versus pages that do not. Pages with credentialed clinical attribution typically convert at 15 to 30 percent higher rates than equivalent pages with anonymous bylines because the trust signal lifts the conversion path along with the discovery path.
The combination of these three metrics tells you whether the moat is widening. Operators who run this measurement framework for 12 to 18 months and consistently invest in clinician contribution produce defensible authority positions that show up across both organic ranking and AI citation surfaces.
What this means for content team structure
The 2026 BH content team structure looks different from the 2022 model. Three roles matter.
Content lead. Non-clinical, focused on editorial planning, SEO strategy, cluster architecture, and workflow management. This is the role most agencies fill today. Skills are SEO, writing direction, project management.
Clinical contributor(s). Licensed clinicians on staff or under advisory contract who provide the interview content, quotes, and bylines. Most BH operators need 2 to 4 contributors with varied specialties. The hours commitment is 4 to 12 hours per month per contributor, which most clinicians can absorb without breaking their primary clinical work.
Drafting writer. Non-clinical writer with healthcare or BH domain knowledge who can produce strong first drafts incorporating the clinician quotes. This role can be full-time, part-time, or freelance depending on volume. AI tools assist with drafting but do not replace the writer.
The cost structure for this model lands at $12,000 to $25,000 a month for most BH operators producing 4 to 8 pieces a month. Operators trying to run this model at $5,000 a month with AI-only production produce volume without authority and get the citation results that match. Operators running it at $30,000+ a month often over-invest relative to the citation lift available.
The right framing is that content is no longer a commodity in 2026. It is an authority investment, and the operators treating it as commodity will be cited at commodity rates by the AI engines that increasingly mediate treatment-seeking discovery. The broader behavioral health marketing program compounds only when the content layer is built on credentialed authority.
Frequently Asked Questions
Can we use AI tools at all if we are building this moat?
Yes, AI tools are useful for drafting support, SERP analysis, outline structure, and editorial review. The constraint is that AI tools should not produce the clinical content itself. The quotes, the case observations, the specific clinical claims need to come from real clinicians. AI assistance on the surrounding structure (introductions, navigation, summary sections, FAQ wrap-ups) is fine and saves time.
The line to hold is that the credentialed clinical voice cannot be manufactured. AI tools can amplify what a real clinician contributes. They cannot replace the contribution. Operators who try to use AI to generate the clinical content and then attribute it to a real clinician are creating reputation and compliance risk that compounds over time.
The practical workflow for most BH content teams is roughly 30 to 40 percent AI-assisted (research, outline, polish) and 60 to 70 percent human-written with clinician contribution. The AI percentage is higher for purely technical or logistical content (insurance verification process explainers, what-to-expect logistical content) and lower for clinical or outcomes content.
How much should we be paying for clinician contribution?
For staff clinicians, the cost is usually absorbed into existing compensation, with content contribution allocated as 2 to 5 percent of their working hours. The 2 to 5 percent allocation produces 4 to 12 hours per month per clinician for content work.
For advisory contracts with external clinicians, the rates land at $1,500 to $4,000 per month depending on the contributor’s seniority and the deliverables expected. The contract should cover interview time, quote contribution, byline attribution, and review hours.
The total monthly content cost (clinician + writer + editorial) for a working BH content program in 2026 lands at $12,000 to $25,000 a month. Operators spending less are usually producing AI-heavy content without the authority signal. Operators spending more are usually over-staffed relative to the citation lift available.
What happens if we cannot get clinical buy-in for this model?
This is the most common blocker. Clinicians are busy, content marketing is not their primary work, and the ask can feel like additional administrative burden. The fix is structural: build the lowest-friction process possible (async voice memos rather than scheduled interviews, batch quote extraction rather than per-piece input, clear deliverables and time commitment caps).
Operators who present the model as “we need 4 hours a month of your time to position you as a published expert with credentials that compound over your career” often get faster buy-in than operators who present it as “we need you to write content for marketing.” The framing matters because the actual benefit to the clinician (credential building, professional profile development, future career optionality) is real.
For operators where no clinician buy-in is possible, the alternative is the advisory contract model with an external clinician who serves multiple operators. The contributor’s name appears across multiple sites, which is acceptable for the AI citation purposes but does not produce the deep operator-specific entity authority that an internal clinical author does.
Does this matter for outpatient and lower-acuity programs the same way?
The moat is more consequential for residential and high-acuity programs where the family-buyer is doing extensive research before admission and where AI citation surfaces are part of that research. Outpatient and lower-acuity programs face less of this dynamic because the buyer journey is shorter and the research stage is briefer.
Still, the underlying signal weights apply across all healthcare content. Even outpatient programs benefit from credentialed clinical attribution on their content, just at a smaller absolute lift. The right calibration for outpatient is roughly half the clinician contribution volume that residential operators run (2 to 4 pieces a month rather than 4 to 8).
For MAT, IOP, and other lower-acuity offerings, the clinical attribution on service pages and the foundational pillar content still produces meaningful citation lift even if the overall content volume is lower.
How do we know if our current content is AI-flagged by the retrieval models?
There is no direct flag visible to operators. The proxy signals are: AI Mode and ChatGPT citation rate across tracked prompts (low or zero citations on relevant queries is a warning sign), AI Overviews appearance rate (declining or stagnant despite cluster investment is a warning sign).
A third signal: organic ranking patterns where pages earn ranking but no AI citation are increasingly visible in the report. Operators who suspect their content is being discounted should pull 10 to 20 representative prompts in their cluster and check whether any of their content appears as a cited source.
If the citation rate is under 10 percent across the basket while competitors with smaller content libraries are being cited more often, the discounting pattern is probably active. The fix is the human-in-the-loop model in this piece. Operators who shift to credentialed clinical contribution start to see citation lift within 60 to 120 days of consistent application, with the lift compounding through 9 to 18 months as the author entity signals strengthen.
What is the single highest-impact change we can make today?
Add a named credentialed clinical author byline to your three highest-traffic pages, with Person schema deployed including jobTitle, knowsAbout for the page topic, and sameAs to LinkedIn at minimum. This is the highest-impact change available because it shifts the page from anonymous attribution to credentialed attribution without requiring any new content production.
The retrieval models pick up the change inside 30 to 60 days. The follow-up move is to add 2 to 4 verbatim clinician quotes to each of those three pages, sourced through the interview or voice memo model in this piece.
The combined effect (named credentialed byline + embedded clinician quotes) often produces 40 to 80 percent citation rate lift within 90 days. The math is favorable: 4 to 6 hours of clinician time produces a citation lift that compounds for years.
The perspective in this article comes from 9 years working exclusively inside behavioral health.
We are a team built by people in recovery who understand that behind every admission is someone asking for help. If that resonates, get to know us.
Trevor Gage is the Director of Earned & Owned Media at Webserv, where he leads SEO, content strategy, and organic acquisition for behavioral health treatment centers. He has overseen audits of more than 200 behavioral health sites and writes about the technical and editorial SEO standards Webserv applies to client work.