A 38-bed residential treatment center asked me last spring why their facility was never cited in ChatGPT or Google AI Mode answers, even though they had a strong site, real clinical depth, and 18 months of disciplined content publishing. I ran their site through three diagnostic checks.
The site had zero Organization schema deployed. The team had no Person schema for the clinical authors writing the blog. The “About” page named the executive director but did not link to any external authority profiles (LinkedIn, the Joint Commission Quality Check listing, Psychology Today).
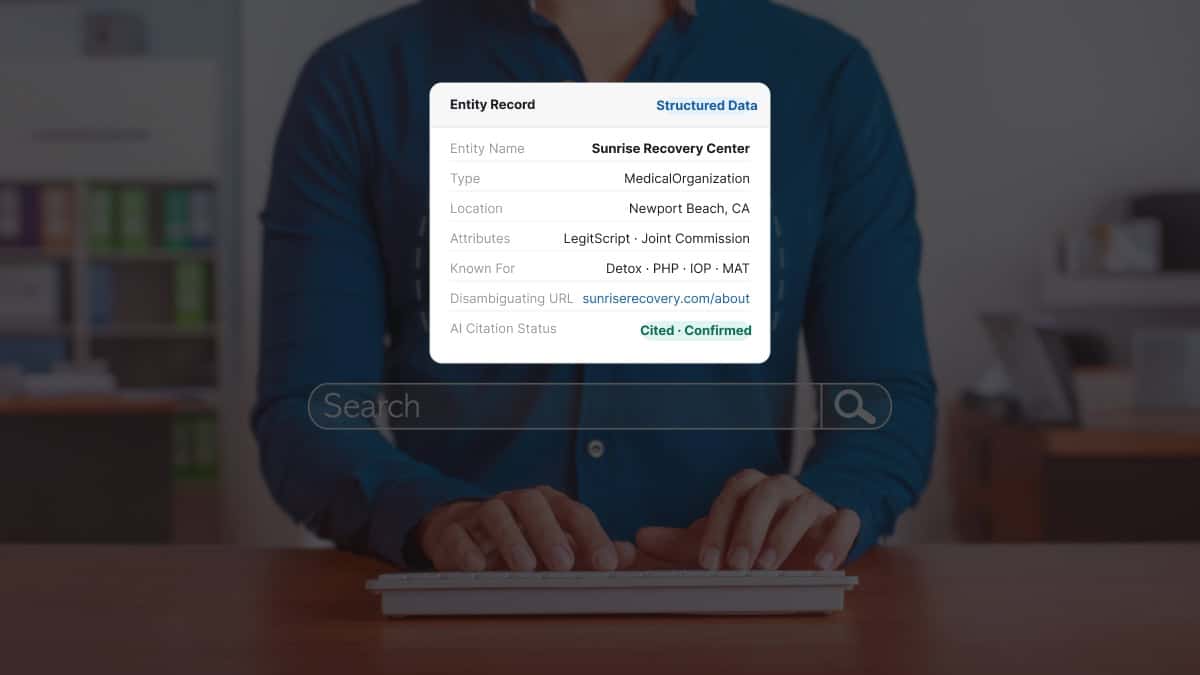
And the Knowledge Graph showed no entity record for the facility at all. Google’s reasoning engine could not confidently identify what the facility was, where it operated, or what it specialized in.
We deployed an entity schema package over six weeks. Organization schema with knowsAbout declarations for the facility’s clinical specialties. LocalBusiness schema anchoring the facility to its physical address. Person schema for each clinical author with credentials and sameAs links to their professional profiles. MedicalClinic and MedicalSpecialty schema for the treatment programs.
Inside 90 days, the facility started appearing as a cited source in AI Mode answers for queries about residential treatment in their region, dual diagnosis care, and the specific modalities they specialize in. The content had been good the whole time. The retrieval layer had not been able to find it because nothing identified the facility as a known entity worth citing.
That gap is the entity SEO gap, and most behavioral health operators have it. The shift from keyword-based search to entity-based AI retrieval is the most consequential change in organic discovery since the mobile-first index.
The treatment centers that win in 2026 are the ones whose AEO program treats their organization, their clinicians, their services, and their locations as machine-readable entities, not as keyword targets. That entity infrastructure is what our AEO practice deploys first on every new client engagement.
Key Takeaways
- Entity SEO is the practice of optimizing for the entities (organizations, people, places, services, conditions) that search engines recognize in their Knowledge Graphs, rather than for keyword strings. Entity-based ranking has largely replaced keyword-only ranking in 2026.
- Google’s AI Mode, ChatGPT Search, Perplexity, and Claude all use entity recognition during retrieval. Sites with clean entity schema get cited more often because the AI can confidently resolve who or what the source is.
- The
knowsAboutproperty is the highest-ROI 2026 schema change for topical authority. Declaring the specific clinical and operational topics your organization has expertise in creates a signal AI engines use when selecting sources for queries in those domains. - Treatment centers need Organization, LocalBusiness, MedicalClinic, Person (for authors), and MedicalSpecialty schema deployed consistently across the site, plus
sameAslinks to authority profiles (LinkedIn, ASAM, Psychology Today, JCAHO). - Entity SEO compounds over time. Sites that deploy entity schema correctly see measurable improvements in AI citation rates over 30 to 60 days, with the lift concentrated in query categories the organization has declared topical authority on.
What Entity SEO actually is
Entity SEO is the discipline of optimizing for the conceptual entities that search engines and AI reasoning engines understand, instead of for the keyword strings users type. The shift sounds small. It is not.
A keyword-based search engine sees the query “residential treatment for opioid addiction in San Diego” as a string of words and tries to match those words to pages on the web.
An entity-based search engine sees the same query as a combination of three entities (residential treatment, opioid addiction, San Diego) plus the implicit fourth entity the user is asking for (a specific treatment provider). The engine then looks for sources that have established themselves as authoritative on each of those four entities and synthesizes the answer from those sources.
The implication is that ranking in 2026 is decreasingly a function of “does your page have the right keywords” and increasingly a function of “is your organization a recognized entity for the topics in this query.”
A page that targets the right keywords on a site with no entity recognition will lose the citation to a page on a site with stronger entity recognition, even if the keyword targeting is technically better.
This is the architecture Google has been building toward since the Knowledge Graph launched in 2012, and it sits on top of the broader AI Overview and ChatGPT citation environment that treatment centers now compete inside.
The Hummingbird update in 2013 introduced entity-driven query interpretation. BERT in 2019 added language model understanding of entity relationships. The 2024-2026 wave of generative AI search built the retrieval and reasoning layers on top of the entity foundation Google had been laying for a decade.
The treatment centers that adopted entity-first SEO between 2018 and 2022 are the ones that show up in AI answers today. The treatment centers still optimizing for keyword strings are increasingly invisible.
How AI search engines actually use entities
The mechanism is worth understanding because it shapes what the optimization work looks like. Three stages matter.
 Infographic titled ‘How AI engines resolve entities during retrieval’ showing how the four major AI search engines handle the three-stage entity retrieval flow, structured as a 4-column-by-3-row comparison grid. Engine columns left to right are Google AI Mode, ChatGPT Search, Perplexity, and Claude. Retrieval stage rows top to bottom are Entity Recognition, Source Selection, and Answer Synthesis. Entity Recognition: AI Mode uses native Knowledge Graph integration; ChatGPT uses entity recognition via OpenAI’s reasoning layer; Perplexity uses entity recognition with explicit citation focus; Claude uses entity recognition with conservative source weighting. Source Selection: AI Mode filters out sites without entity signals at retrieval; ChatGPT prioritizes sites with strong Organization schema; Perplexity prioritizes sites that resolve cleanly as named entities; Claude prioritizes sites with clear identity disambiguation. Sites with clean entity schema get cited more often because AI can confidently resolve who or what the source is. Good content alone does not earn AI citations in 2026.
Infographic titled ‘How AI engines resolve entities during retrieval’ showing how the four major AI search engines handle the three-stage entity retrieval flow, structured as a 4-column-by-3-row comparison grid. Engine columns left to right are Google AI Mode, ChatGPT Search, Perplexity, and Claude. Retrieval stage rows top to bottom are Entity Recognition, Source Selection, and Answer Synthesis. Entity Recognition: AI Mode uses native Knowledge Graph integration; ChatGPT uses entity recognition via OpenAI’s reasoning layer; Perplexity uses entity recognition with explicit citation focus; Claude uses entity recognition with conservative source weighting. Source Selection: AI Mode filters out sites without entity signals at retrieval; ChatGPT prioritizes sites with strong Organization schema; Perplexity prioritizes sites that resolve cleanly as named entities; Claude prioritizes sites with clear identity disambiguation. Sites with clean entity schema get cited more often because AI can confidently resolve who or what the source is. Good content alone does not earn AI citations in 2026.Entity recognition. When the user submits a query, the AI engine identifies the entities in the query (residential treatment, opioid addiction, San Diego, etc.). It then expands each entity into its Knowledge Graph profile: related concepts, synonyms, geographic context, parent and child topics.
Source selection. The engine looks for sources that have established entity recognition for the topics in the expanded query. Sites with strong Organization schema, declared topical authority, and clean entity disambiguation get prioritized. Sites without those signals get filtered out at the retrieval stage, even if the page content is good.
Answer synthesis. The engine pulls passages from the selected sources and synthesizes the user-facing answer, citing the sources whose entity signals match the query most strongly. This is the same query fan-out architecture that powers AI Mode, decomposing the user prompt into 8 to 12 sub-queries and using entity recognition to rank passages for each sub-query.
The practical implication is that good content alone does not earn AI citations in 2026. Good content on a site that is recognized as an authoritative entity earns citations. The entity layer is what makes the content discoverable to the retrieval system.
For treatment centers, this changes what the optimization work looks like. The content team can produce a 3,000-word piece on dual diagnosis care that is clinically rigorous, structurally clean, and AEO-optimized at the passage level.
If the facility publishing the piece has no Organization schema, no knowsAbout declarations for dual diagnosis, no Person schema on the author, and no Knowledge Graph entity record, the piece will not get cited by the AI engines that are now driving an increasing share of treatment-seeking research traffic.
The entity audit for a treatment center
The starting point is to understand what entity signals your site currently sends and what gaps exist. A 90-minute audit covers most of what matters.
Step 1: Knowledge Panel check. Search your facility name in Google. If a Knowledge Panel appears on the right side of the desktop results, your facility has a basic Knowledge Graph entity record. If no panel appears, the facility is not recognized as a distinct entity, which is the highest-priority gap to close.
Step 2: Schema inventory. Run the homepage and 3 to 5 representative pages through Google’s Rich Results Test. Note which schema types are present. Most BH operator sites I audit have either no schema or generic LocalBusiness schema with no specialization markup.
The target inventory is Organization + LocalBusiness + MedicalClinic + MedicalSpecialty on the homepage, with Article + Person schema on blog content and Service schema on level-of-care pages.
Step 3: sameAs audit. Check whether your Organization schema (if any) declares sameAs properties pointing to LinkedIn, ASAM, JCAHO accreditation listing, Psychology Today, and your state’s treatment provider registry. These external entity references are how Google’s reasoning engine validates that your organization is the same entity across multiple authoritative sources.
Step 4: Author entity check. Pull 5 random blog posts and check whether each one has Person schema for the author, with credentials, jobTitle, and sameAs links to the author’s professional profiles. Most BH sites I audit have anonymous bylines or first-name-only attribution, both of which fail the 2026 E-E-A-T author entity bar.
Step 5: knowsAbout audit. Pull the Organization schema (if present) and check the knowsAbout array.
Most treatment center sites have either no knowsAbout declarations or generic terms like “addiction treatment” and “rehab.” The target declarations are specific clinical topics the facility genuinely specializes in: dual diagnosis, trauma-informed care, medication-assisted treatment, specific clinical modalities, specific populations served.
The audit produces a prioritized gap list. Most operators have all five gaps to some degree. The remediation order I recommend is Organization + LocalBusiness first (foundational), then sameAs external links (entity disambiguation), then knowsAbout declarations (topical authority), then Person schema on authors (E-E-A-T), then MedicalClinic and MedicalSpecialty (clinical entity recognition).
The five schema types every treatment center needs
The 2026 schema stack for behavioral health follows what some practitioners call the “unbroken chain” pattern. Five interconnected schema types deployed consistently across the site.
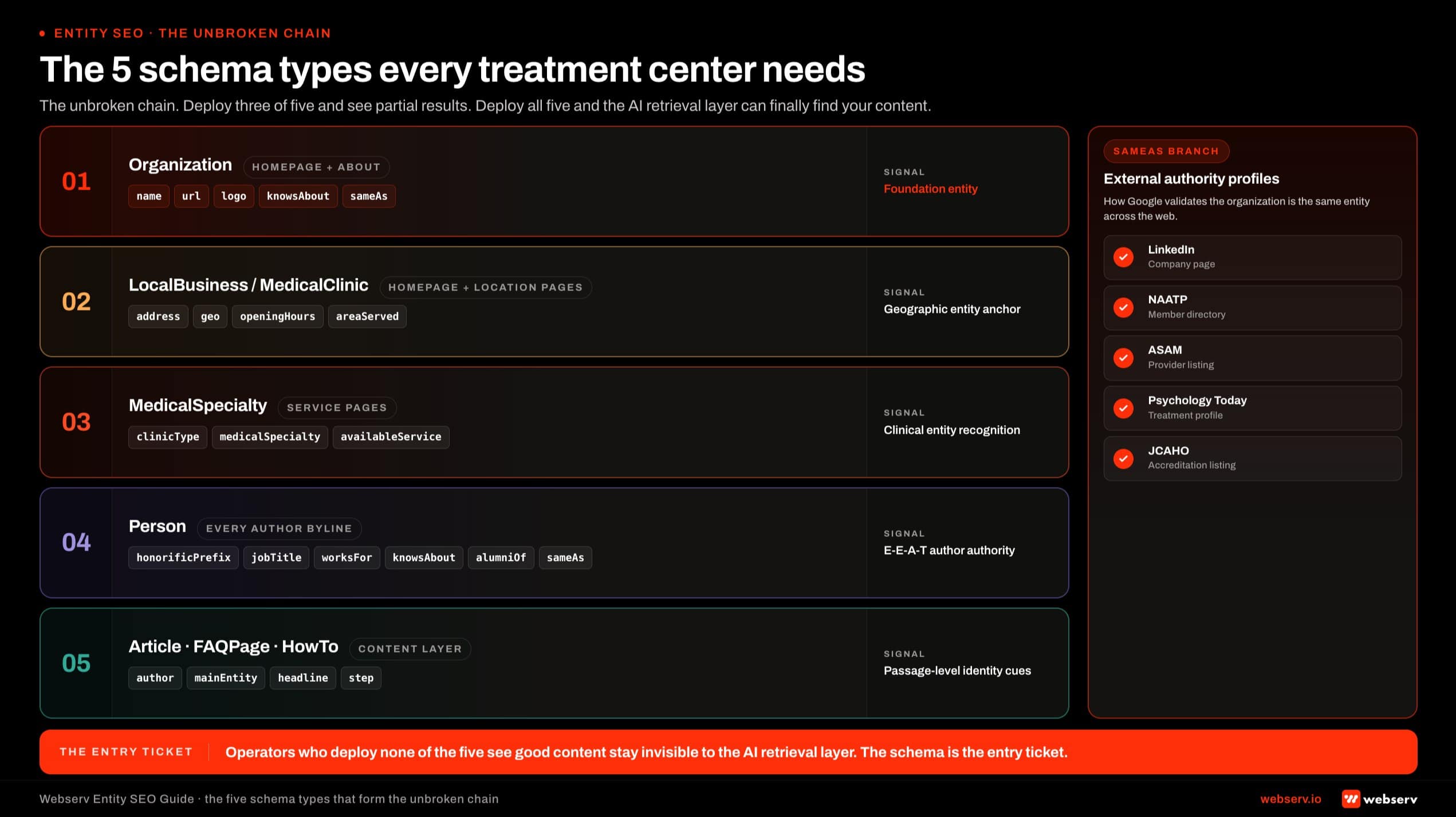 Infographic titled ‘The 5 schema types every treatment center needs’ showing the five interconnected schema types that form the unbroken chain of entity references for treatment center sites, arranged as five horizontal blocks stacked top to bottom with connecting arrows. Block 1 Organization deploys on homepage and About page with knowsAbout and sameAs properties. A side branch shows sameAs destinations LinkedIn, ASAM, Psychology Today, and JCAHO. Block 2 LocalBusiness or MedicalClinic deploys on homepage and location pages with address, geo, hours, and area served. Block 3 MedicalSpecialty deploys on service pages with clinic type, medical specialties, and conditions treated. Block 4 Person deploys on every author byline with honorificPrefix, jobTitle, worksFor, knowsAbout, alumniOf, and sameAs. Block 5 Article, FAQPage, and HowTo deploys on the content layer.
Infographic titled ‘The 5 schema types every treatment center needs’ showing the five interconnected schema types that form the unbroken chain of entity references for treatment center sites, arranged as five horizontal blocks stacked top to bottom with connecting arrows. Block 1 Organization deploys on homepage and About page with knowsAbout and sameAs properties. A side branch shows sameAs destinations LinkedIn, ASAM, Psychology Today, and JCAHO. Block 2 LocalBusiness or MedicalClinic deploys on homepage and location pages with address, geo, hours, and area served. Block 3 MedicalSpecialty deploys on service pages with clinic type, medical specialties, and conditions treated. Block 4 Person deploys on every author byline with honorificPrefix, jobTitle, worksFor, knowsAbout, alumniOf, and sameAs. Block 5 Article, FAQPage, and HowTo deploys on the content layer.Organization schema on the homepage and About page. Declares the facility as an entity. Includes name, URL, logo, founding date, founder, contact info, sameAs properties pointing to LinkedIn and authoritative directories, and the critical knowsAbout property declaring the topical domains where the organization has expertise. Schema.org’s Organization documentation covers the full property set.
LocalBusiness schema (or its specialization MedicalClinic) on the homepage and location pages. Anchors the facility to a specific physical address with geo coordinates, hours of operation, payment methods accepted, and area served. This is the entity signal that connects your facility to geographic queries, and the foundation that the local SEO playbook builds the Google Business Profile and citation layer on top of.
MedicalClinic and MedicalSpecialty schema on service pages. Identifies the clinic type, the medical specialties offered (psychiatry, addiction medicine, dual diagnosis), and the conditions treated. This is what makes the facility discoverable for clinical queries that go beyond simple geography.
Person schema on every author byline. Declares the author as an entity with credentials, jobTitle, knowsAbout topics, alumniOf for education, and sameAs properties pointing to the author’s LinkedIn, professional licensure records, and any other authoritative profiles. This is the E-E-A-T author signal Google’s quality systems weigh on YMYL content.
Article, FAQPage, and HowTo schema on the content layer. Identifies blog posts as Article entities (with author Person references), FAQ blocks as FAQPage entities, and procedural content as HowTo entities. Per Google Search Central’s structured data documentation, this is what gives the retrieval layer explicit identity cues for each passage on the page. The same logic our healthcare blog and article writing standards build around.
The five types interconnect through entity references. The Article’s author Person references back to the Organization. The Organization references the LocalBusiness/MedicalClinic. The MedicalSpecialty references the Organization. The result is an unbroken chain of entity relationships that the AI reasoning engines can traverse to validate authority and assess source credibility.
Operators who deploy three or four of the five but skip one or two see partial results. Operators who deploy the full chain see compounding lift. Operators who deploy none see the pattern in my opening story: good content invisible to the AI retrieval layer because nothing identifies the source as a recognized entity.
“Good content alone does not earn AI citations in 2026. Good content on a site that is recognized as an authoritative entity earns citations.”
Preston Powell, Chief Executive Officer, Webserv
knowsAbout: the 2026 lever most operators miss
Among the five schema types, the knowsAbout property on Organization and Person schema is the single most underweighted lever in 2026. The 2025-2026 update cycle made knowsAbout declarations roughly the second most impactful entity markup available, behind only the basic Organization entity recognition itself.
The property declares the topics your organization or your authors have expertise in. AI Mode uses these declarations when selecting sources for specific query categories.
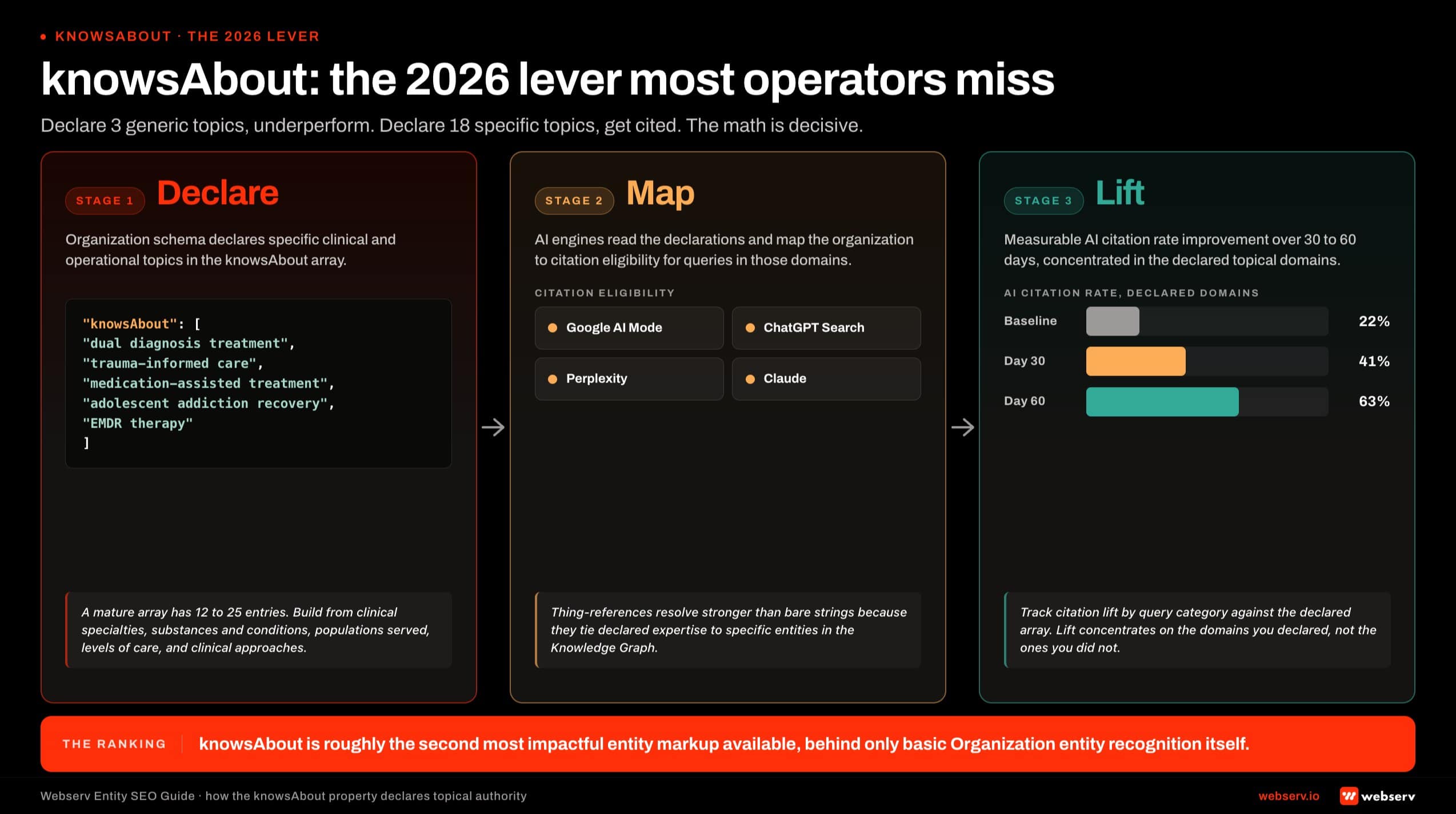 Infographic titled ‘knowsAbout: the 2026 lever most operators miss’ showing how the knowsAbout property on Organization schema declares topical authority and produces measurable AI citation lift, structured as a three-column left-to-right flow with connecting arrows. Column 1 Declare shows the knowsAbout array as a code-style block with example values dual diagnosis treatment, trauma-informed care, medication-assisted treatment, adolescent addiction recovery, and EMDR therapy. Column 2 Map shows an AI engine node with arrows fanning out to citation eligibility across AI Mode, ChatGPT Search, Perplexity, and Claude. Column 3 Lift shows measurable AI citation rate lift over 30 to 60 days concentrated in declared topical domains. Mature knowsAbout arrays have 12 to 25 entries; operators declaring 3 generic topics underperform operators declaring 18 specific topics. knowsAbout is the second most impactful entity markup available behind only basic Organization entity recognition.
Infographic titled ‘knowsAbout: the 2026 lever most operators miss’ showing how the knowsAbout property on Organization schema declares topical authority and produces measurable AI citation lift, structured as a three-column left-to-right flow with connecting arrows. Column 1 Declare shows the knowsAbout array as a code-style block with example values dual diagnosis treatment, trauma-informed care, medication-assisted treatment, adolescent addiction recovery, and EMDR therapy. Column 2 Map shows an AI engine node with arrows fanning out to citation eligibility across AI Mode, ChatGPT Search, Perplexity, and Claude. Column 3 Lift shows measurable AI citation rate lift over 30 to 60 days concentrated in declared topical domains. Mature knowsAbout arrays have 12 to 25 entries; operators declaring 3 generic topics underperform operators declaring 18 specific topics. knowsAbout is the second most impactful entity markup available behind only basic Organization entity recognition.An organization with knowsAbout declarations for “dual diagnosis treatment,” “trauma-informed care,” “medication-assisted treatment,” and “adolescent addiction recovery” is more likely to be cited for queries in those domains than an equivalent organization with no topical authority declarations or with generic declarations like “addiction treatment.”
The implementation is simple to describe and easy to do badly. The Organization schema’s knowsAbout property accepts an array of either string values (“dual diagnosis treatment”) or Thing references to specific concept entities. The string approach works for general visibility. The Thing-reference approach is stronger because it ties your declared expertise to specific entities in the broader Knowledge Graph.
A reasonable starting knowsAbout array for a residential treatment center looks like:
- Specific clinical specialties (dual diagnosis, trauma treatment, medication-assisted treatment, EMDR)
- Specific substances and conditions treated (alcohol use disorder, opioid use disorder, polysubstance, methamphetamine)
- Specific populations served (adults, adolescents, women, veterans, professionals, LGBTQ+ specific)
- Specific levels of care offered (residential, PHP, IOP, MAT, detox, outpatient)
- Specific clinical approaches (CBT, DBT, family therapy, group therapy, somatic experiencing)
A typical mature knowsAbout array for a multi-program facility has 12 to 25 entries. Operators who declare 3 generic topics underperform operators who declare 18 specific topics, even when the underlying content is comparable.
How SoCal Sunrise generated 85 admissions and 2,297% ROI from SEO in 6 months
A ground-up SEO rebuild using the Pathfinder Parents Methodology turned an invisible online presence into a top-ranking admissions engine.
Read the case study →85 admits and 3,152 leads attributed to organic
Author entity and the E-E-A-T entity signal
The 2026 update cycle made author entity recognition table stakes for YMYL healthcare content. A blog post with an anonymous byline or a first-name-only attribution is increasingly invisible in YMYL rankings, while a blog post with a credentialed Person entity behind it accumulates author-level authority that compounds across the cluster.
The Person schema for a clinical author should declare:
- Full name and
honorificPrefix(LCSW, LMFT, MD, PhD) jobTitleand role at the organizationworksForreference back to the Organization entityknowsAbouttopics specific to the author’s clinical expertisealumniOffor medical school, graduate school, professional training programssameAslinks to LinkedIn, state licensure records, Psychology Today profile, professional society listings (ASAM, APA, AMA)
The deployment pattern is to embed the Person schema on the author byline of every piece they have written, with consistent entity identity across pieces. An author who has written 30 posts with consistent Person schema is a stronger entity signal than the same author with inconsistent or missing schema across pieces.
For treatment centers running the clinical-reviewer model where a senior clinician reviews content drafted by non-clinical writers, the Person schema attaches to the reviewer. The byline can include both names (writer and reviewer), but the entity authority signal lives with the credentialed reviewer.
The compounding effect is what makes this matter. Sites that build a small library of consistent author entities (3 to 6 credentialed clinicians, each with Person schema and a sustained byline history) develop topical authority faster than sites with rotating anonymous content. The author entity is the bridge between content quality and organizational authority, and Google’s reasoning engines use it as a primary trust signal.
How entity SEO compounds with the rest of the AEO program
Entity SEO is not a standalone discipline. It is the substrate that makes the rest of the AEO work productive. Three adjacent layers compound with the entity work.
Passage-level content optimization. The fan-out query architecture rewards content with atomic answer paragraphs, semantic triples, and clean H2/H3 structure. Entity SEO determines whether your site is in the candidate set for retrieval at all. Passage optimization determines whether your passages get selected once the site is in the candidate set. Both layers matter. Neither works alone.
Topical cluster depth. Entity declarations only land if the surrounding content supports them. An Organization declaring knowsAbout for “trauma-informed care” with no content cluster on trauma-informed care reads as an unsubstantiated claim and gets discounted. The content cluster work that builds out depth on each declared topic is what gives the entity signals credibility. Entity SEO and cluster architecture are two sides of the same authority-building process.
Technical SEO foundation. Schema deployment requires a clean technical SEO foundation underneath. Schema that does not validate, schema that conflicts between page types, schema that is missing on key pages — the same pattern that doorway page clusters create at the content layer, where unresolvable signals get the entire site discounted. All of these undermine the entity signal. New facilities have it easier here: the foundational site work a new treatment center ships first builds this base before the content layer exists.
Sites with strong schema architecture on a clean technical base see the full lift from entity work. Sites with schema layered onto a broken technical foundation see degraded results, especially on sites still working through mobile-first indexing issues that affect how schema renders to crawlers.
The synthesis is that entity SEO is the highest-ROI AEO investment a treatment center can make right now, but only if the content, cluster, and technical layers are healthy enough to support it. Operators who try to deploy entity schema as a standalone fix on a thin content site see modest improvement. Operators who deploy entity schema as the top layer of an already-mature content and technical program see transformative improvement in AI citation rates. For operators considering external help, the AI optimization agency selection question maps directly to this stack maturity assessment, and the broader behavioral health marketing program compounds when entity work runs alongside the rest.
Frequently Asked Questions
How is entity SEO different from traditional SEO?
Traditional SEO optimizes for keyword matching: produce pages that target specific queries, with the queries reflected in the title, headings, and body content. Entity SEO optimizes for entity recognition: establish the organization, its services, its locations, its clinicians, and its topical expertise as recognized entities in Knowledge Graphs that AI reasoning engines use during retrieval.
The two are not opposed. Entity SEO does not replace keyword targeting. It sits above it. A page can be perfectly keyword-targeted and still fail to earn citations if the underlying organization is not a recognized entity. Conversely, a page with mediocre keyword targeting can earn citations if the organization has strong entity authority on the topic.
The practical shift is that the unit of optimization is no longer just the page. It is the page plus the entity (organization, author, service, location) the page belongs to. Sites that optimize at both levels win the 2026 retrieval game. Sites that only optimize at the page level lose share to entity-strong competitors.
What is the Knowledge Graph and why does it matter for treatment centers?
The Knowledge Graph is Google’s database of entities (people, places, things, concepts) and the relationships between them. It launched in 2012 and now powers Knowledge Panels, AI Mode, AI Overviews, and the entity recognition layer underneath Google’s broader search infrastructure.
For treatment centers, the Knowledge Graph matters because AI reasoning engines use it to resolve “who is this source” during answer synthesis. A facility with a Knowledge Graph entity record (the kind that produces a Knowledge Panel when you search the facility name) is treated as a known, verifiable entity by the AI engines. A facility with no record is treated as ambiguous, which makes the engines less likely to cite content from that source.
Getting into the Knowledge Graph requires entity disambiguation through schema, consistent NAP (name, address, phone) signals across the web, citations from authoritative directories (ASAM, JCAHO, Psychology Today, state registries), and external authority profiles linked through sameAs properties. The process typically takes 3 to 9 months for a facility starting from no record.
Will deploying schema actually move our AI citation rates?
Yes, and the timeline is faster than most operators expect. Evidence from sites that have tested schema implementations post-March 2026 shows measurable AI Mode citation improvement over a 30 to 60 day window after deployment, with the lift concentrated on queries in the site’s declared topical authority areas.
The variation in outcomes comes from the gap between the schema and the content. Sites with strong existing content and a missing entity layer see large jumps when the schema is deployed because the entity signals open up the content’s discoverability. Sites with thin content and full schema deployment see smaller jumps because the schema cannot manufacture authority that the underlying content does not support.
The right framing is that schema deployment is the highest-ROI move for sites that have the content but lack the entity signal. For sites still building the content, schema work should run in parallel with content work, not after it.
Do we need to hire a developer to deploy schema?
For basic Organization, LocalBusiness, and Article schema, no. Most WordPress sites can deploy these through SEO plugins (Yoast, Rank Math, Schema Pro) with no custom development required. The plugins generate JSON-LD that covers the foundational entity types.
For advanced schema (MedicalClinic specializations, custom knowsAbout arrays, multi-author Person schema with cross-references, FAQPage with multiple Q&A entities), some developer time is usually needed to extend the plugin output or to deploy custom schema templates. The work is typically 8 to 20 hours of developer time for a mid-sized treatment center site, plus ongoing maintenance as new content publishes.
For multi-location operators, schema deployment at scale benefits from a dedicated schema management tool or a custom implementation that holds consistency across location-specific pages. The cost of getting this wrong (conflicting schema between location pages, generic schema where specific schema is needed) is much higher than the cost of doing it right the first time.
How does entity SEO interact with our existing local SEO program?
Entity SEO strengthens local SEO and vice versa. The two overlap on LocalBusiness schema, geographic entity associations, and the citations across authoritative directories that build both local pack visibility and Knowledge Graph entity recognition.
Entity SEO adds a layer on top: ensuring the LocalBusiness schema on your site is specialized to MedicalClinic, declaring knowsAbout for the specific clinical topics relevant to the local market, and linking the local entity to broader authority signals through sameAs properties.
Operators who run local SEO without entity SEO win the local pack but lose AI citations. Operators who run entity SEO without local SEO win some AI citations but underperform in local commercial queries. The two together produce the strongest results for treatment centers because both surfaces matter: the local pack drives clicks, the AI citations drive trust.
What is the right starting point if we are doing none of this today?
Start with the entity audit (Knowledge Panel check, schema inventory, sameAs audit, author entity check, knowsAbout audit) and prioritize the gaps. For most operators starting from zero, the right order is:
- Deploy Organization and LocalBusiness schema on the homepage and About page with full property coverage including
sameAsto LinkedIn, ASAM, and JCAHO - Add
knowsAboutdeclarations for 15 to 25 specific clinical topics the facility genuinely specializes in - Specialize the LocalBusiness schema to MedicalClinic on location pages
- Deploy Person schema for 3 to 6 credentialed clinical authors with consistent attribution across content
- Add MedicalSpecialty and Service schema on level-of-care pages
- Layer Article, FAQPage, and HowTo schema across the content layer
The full deployment typically takes 6 to 10 weeks for a mid-sized facility, with the AI citation lift starting to appear at 30 days and compounding through 90 to 120 days. Operators who start this work earlier than competitors capture meaningful early-mover advantage as the AI retrieval surface continues to expand.
The perspective in this article comes from 9 years working exclusively inside behavioral health.
We are a team built by people in recovery who understand that behind every admission is someone asking for help. If that resonates, get to know us.
Trevor Gage is the Director of Earned & Owned Media at Webserv, where he leads SEO, content strategy, and organic acquisition for behavioral health treatment centers. He has overseen audits of more than 200 behavioral health sites and writes about the technical and editorial SEO standards Webserv applies to client work.