A treatment center we work with started 2026 with a question we have been getting every week since AI Overviews became unavoidable.
The marketing director had read about ChatGPT citations, schema, llms.txt, MCP servers, the Open Knowledge Format, AI Information pages, and a dozen other surfaces that newsletters and conference talks were treating as load-bearing.
The vendors pitching her each had a different “must-have.”
Her actual question was simpler. What is the full stack she needs to ship, in what order, with which trade-offs, and how does she know it is working.
This article is the answer. The full AI search stack for treatment centers, with the implementation order, the trade-offs, and the measurement layer that ties the work back to admit-attributed conversion.
The frame is built around the four phases we walk operators through inside our content SEO program for treatment centers and synthesizes what Google’s June 2026 generative AI optimization guide made explicit.
Three composite numbers below from the treatment center we used as the anchor for this guide. Each came from the same 90-day reorganization that put the stack in place.
4x
AI Overview citation share for condition-cluster queries
+31%
Admit-attributed conversion from organic traffic
0 → 8
Citations across ChatGPT, Claude, Perplexity in 90 days
The rest of this article walks the stack from foundation to measurement.
Key Takeaways
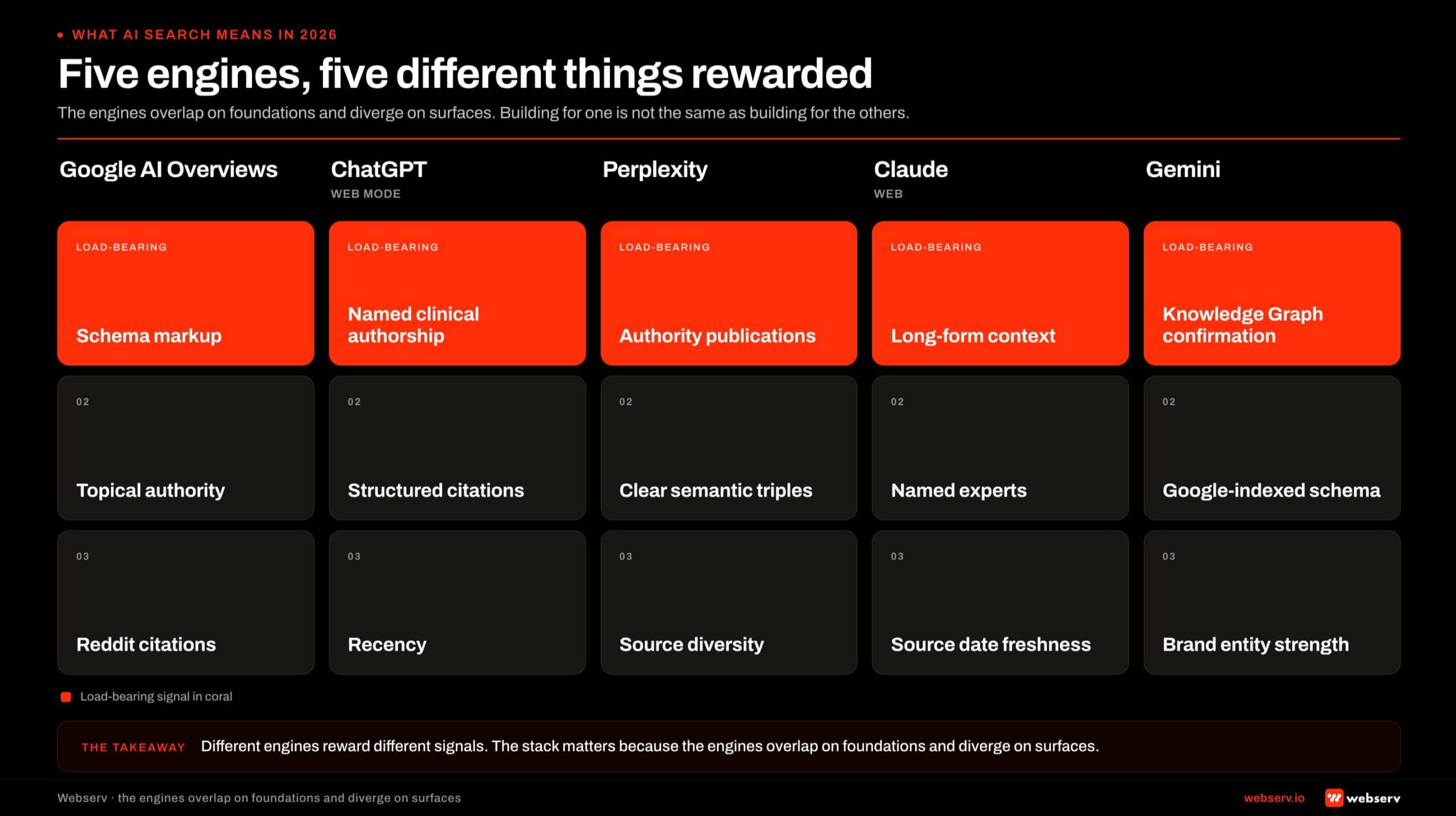
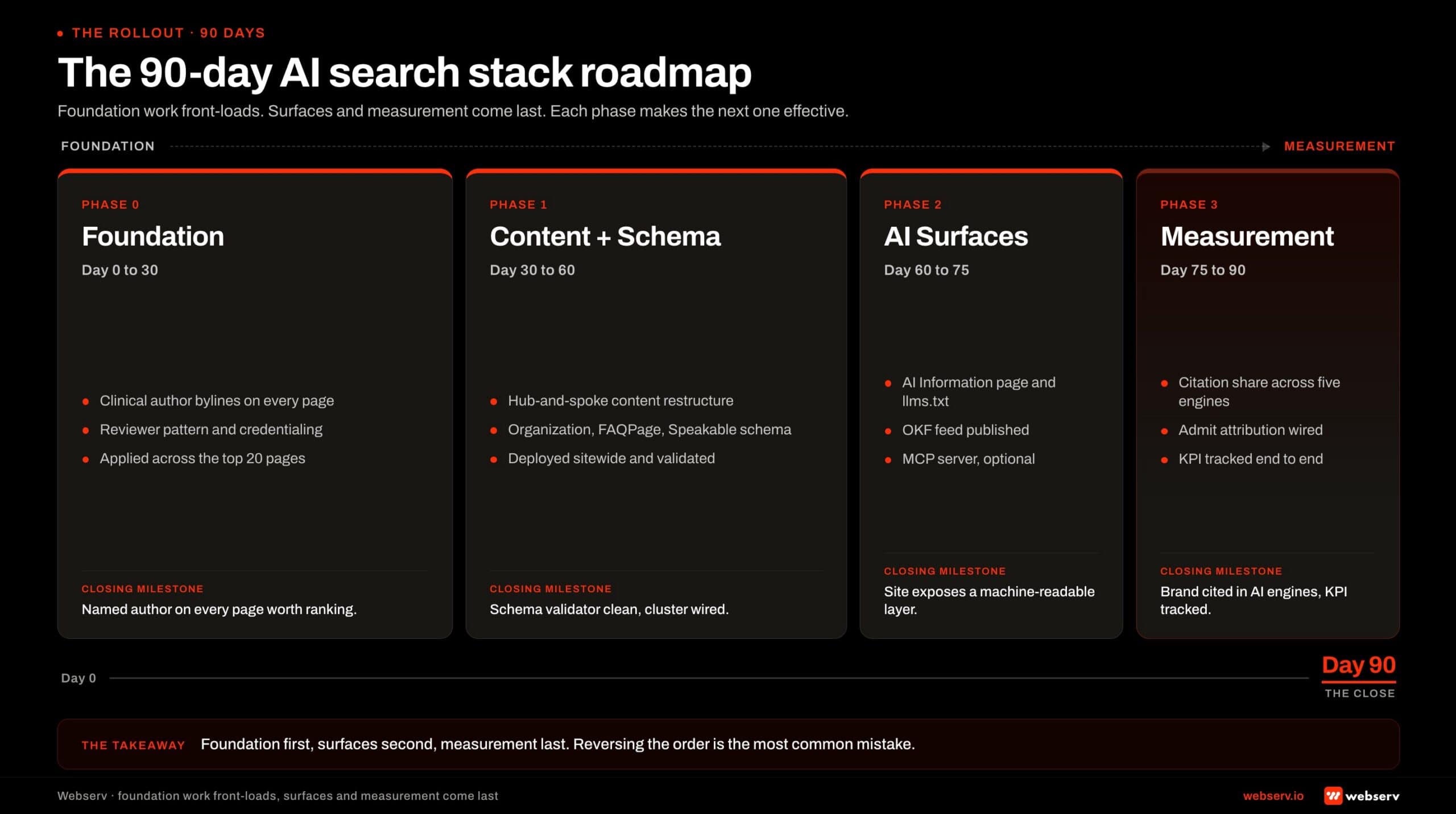
- The AI search stack for treatment centers has four phases: foundation (E-E-A-T plus technical SEO), content (non-commodity content with named clinical authorship), infrastructure (schema plus the optional AI-specific surfaces), and measurement. The phases are sequential. Skipping ahead produces less compounding lift than sequencing the work correctly.
- Per Google’s June 2026 official guidance, optimizing for generative AI search is still SEO. AI Overviews rely on Google’s core ranking systems, and the architecture that ranks well for classic organic search is the architecture that earns AI citation share. The AEO-vs-SEO frame the industry built in 2023-2024 is unified, not split.
- Named clinical authorship is non-negotiable. AI search systems weight Experience, Expertise, Authoritativeness, and Trustworthiness signals at the YMYL threshold for healthcare, and clinician-credentialed content is the load-bearing signal that separates cited sources from invisible ones.
- The optional AI-specific surfaces (llms.txt, OKF bundles, MCP servers, AI Information pages) carry weight outside Google Search even though Google says it does not use llms.txt for ranking. Operators investing in these should size the investment to the non-Google AI surface they want to influence rather than expect Google ranking lift.
- Measurement matters more than tactics. The right framework tracks citation share across at least four AI surfaces (Google AI Overviews, ChatGPT, Claude, Perplexity) and ties it back to admit-attributed conversion via 60- to 120-day attribution windows. Without measurement, the operator cannot tell which layer of the stack is producing the lift.
PHASE 1 · FOUNDATION
What “AI Search” Actually Means in 2026
Before the stack makes sense, the operator needs a shared vocabulary for what AI search systems actually do. Two technical concepts drive every architectural decision below.
DEFINITION
Retrieval-Augmented Generation (RAG)
How AI search features ground their answers. The model pulls candidate sources from Google’s Search index, then generates a response that cites those pages. The underlying ranking systems determine which sources get retrieved.
The second mechanic is query fan-out. AI systems decompose a single user question into 6 to 15 concurrent sub-queries (interventions, MAT, family resources for a question about “fentanyl treatment for my son”), each routed through Google’s ranking. The cited sources are the union of what gets retrieved across the fan-out set.
These two mechanics explain why the AEO-vs-SEO debate ended. The model retrieves from the same index your classic organic results sit in, and the fan-out queries it runs are evaluated by the same ranking systems.
The architecture that produces strong classic organic ranking is the architecture that produces strong AI citation share.
What the AI search shift does change is the emphasis. Google’s guidance now centers on non-commodity content (experience-led perspective) over commodity content (recyclable common knowledge).
For treatment centers, this is the difference between a clinician’s first-hand reflection on co-occurring disorder assessment and a generic “what is dual diagnosis” explainer.
The first earns citation share. The second sits in the long tail of commodity content that the post-2025 systems explicitly deprioritize.
PHASE 1 · FOUNDATION
The E-E-A-T Foundation Every AI Search Surface Requires
Healthcare YMYL pages face the strictest E-E-A-T threshold of any vertical Google evaluates. The same threshold flows through to AI Overviews, ChatGPT, Claude, and Perplexity because those systems use Google’s ranking signals as part of their source-selection logic.
For the deep-dive on the single signal driving the most citation lift inside E-E-A-T (named clinician quotes), see Clinicians as the AEO Moat: Why Author Quotes Beat Generative AI.
For treatment centers, the foundation has four load-bearing pieces. First, named clinical author bylines on every YMYL article (not “Editorial Team,” not a generic facility staff attribution). Second, named clinical reviewer credit on top of the author byline.
Third, structured author bio pages with credentials, licensure, NPI sameAs links, and a list of authored articles. Fourth, peer-reviewed citations to SAMHSA, NIDA, NIMH, JAMA Psychiatry, and ASAM publications inside the content body.
The author and reviewer pattern is the single most common foundation gap we see. The deeper read lives in how to build clinical content Google trusts and patients actually find and author bios that build E-E-A-T for behavioral health blogs.
Without this foundation, the rest of the stack is publishing into a vacuum.
The technical SEO foundation matters alongside the E-E-A-T layer. Crawlability, schema, internal linking, Core Web Vitals, and site speed all feed into the same ranking systems.
A treatment center site failing Core Web Vitals on mobile competes against a passing competitor at a structural disadvantage in both classic and AI search, regardless of how strong the E-E-A-T signals are.
PHASE 2 · CONTENT LAYER
Non-Commodity Content and Named Clinical Authorship
The content layer is where Google’s June 2026 framing matters most. The official guidance contrasts “7 Tips for First-Time Homebuyers” (commodity, recyclable from common knowledge) against “Why We Waited Five Years to Buy a House” (non-commodity, experience-led, irreducible to public information).
For treatment center content, the same distinction governs whether an article earns citation share or disappears into the long tail.
The commodity-vs-non-commodity test is concrete. Could an AI model write this article from public information alone? If yes, the article is commodity. If no, the article carries the kind of first-hand experience signal both Google and the LLMs explicitly reward.
Named clinician perspective is one of the most reliable ways to make content non-commodity.
The architectural implication runs across the editorial calendar. Articles built primarily to capture keyword variations get categorized as scaled content abuse and produce ranking drag. Articles built around named clinical voice and irreducible operational experience compound.
The cadence question matters less than the perspective question.
COMMON MISTAKE
Producing 8 articles a month with Editorial Team bylines and assuming volume produces ranking. The 184-post commodity library is the most common content footprint we audit, and it correlates with materially worse AI citation share than a 30-post library built around named clinician perspective.
The 8-article-a-month cadence is the trap. The 4-to-6-article-a-month cadence anchored in named clinician perspective is the pattern that compounds.
PHASE 2 · CONTENT LAYER
The Hub-and-Spoke Architecture Updated for AI Search
The hub-and-spoke content architecture remains the dominant pattern for treatment center websites, and the 2026 form retains the core structure with adjustments for how RAG and query fan-out actually retrieve.
The mechanic underneath hub-and-spoke is topical authority : the breadth-and-depth signal that determines whether AI engines treat your site as the authoritative source on a topic.
The five hub categories that anchor admit-driving architecture: condition pillars (alcohol use disorder, opioid use disorder, anxiety, depression, co-occurring, eating disorders) and modality clusters (CBT, DBT, EMDR, medication management, group therapy).
The architecture also covers level-of-care pages (detox, residential, PHP, IOP, outpatient), geographic anchors tied to real facility presence, and the family-facing resource hub.
A hub page runs 2,500 to 6,000 words, anchored by a named clinical author and reviewer, and serves both the human reader and the RAG retrieval pattern.
Spokes orbit each hub, addressing more specific questions inside the cluster with 1,200 to 2,800 word articles that link back to the hub and to relevant cross-cluster spokes.
Internal linking density across the cluster produces the topical authority signal Google’s ranking system rewards and that AI search systems read through to citation eligibility.
The cluster effect compounds across the four phases. A condition pillar with named authorship, peer-reviewed citations, strong schema, and internal links to 8 to 12 spokes earns AI citation share at higher rates than the same pillar in isolation.
The architecture is the multiplier.
PHASE 3 · INFRASTRUCTURE
The Schema Stack That Makes Content Legible
Structured data is the technical infrastructure that helps Google’s ranking systems and AI surfaces disambiguate entities, attribute authorship, and surface FAQ content correctly. Google’s June 2026 guidance specifically calls out that the standard schema.org stack is what ranking systems use.

For treatment centers, four schema types earn their keep.
Organization and MedicalOrganization schema deployed sitewide with a stable @id, anchoring the facility’s entity in Google’s knowledge graph. Article schema with Person author and Organization publisher on every clinical content piece.
FAQPage schema on articles with FAQ blocks, earning featured snippet eligibility. BreadcrumbList schema across the cluster, supporting navigational legibility.
The pattern Google’s guidance specifically deprioritizes is speculative AI-only schema. Custom schema types designed to “help AI systems understand the content” beyond standard schema.org do not produce ranking lift and can flag content as over-optimized.
Operators investing heavily in AI-specific schema work in 2024 and 2025 sometimes overbuilt this layer. The right read in 2026 is to keep the standard schema stack mature and stop there.
PHASE 3 · INFRASTRUCTURE
The Optional AI-Specific Surfaces: AI Information Page, llms.txt, OKF, MCP
The next layer in the stack covers the AI-specific surfaces that emerged after AI Overviews launched. Four surfaces matter for treatment center operators evaluating where to invest.
The AI Information page is a canonical brand-facts page designed for LLM citation accuracy. Structured, label-value formatted, with the facility’s name, founding date, leadership team, accreditations, services, locations, and the relationships between them.
The page is human-readable and crawler-readable. AI systems use it to verify facts about the facility when generating responses.
The pattern is well-established and produces measurable citation accuracy lift across non-Google AI surfaces.
llms.txt is a plain-text site overview at the root of the domain, designed to give AI crawlers a quick orientation to the site. The format is simple and widely discussed in AEO industry conversations.
POSITION UPDATE
Google’s June 2026 documentation clarified what we and most AEO practitioners had treated as an open question. The official quote: "Doing so won’t harm (nor help) your visibility or rankings in Google Search." That refines the read. llms.txt is still worth shipping for non-Google AI surface visibility (ChatGPT, Claude, Perplexity, and emerging AI agents), but the investment should be sized to that surface rather than to Google ranking lift.
The Open Knowledge Format (OKF) is the markdown-plus-YAML bundle format Google Cloud published in June 2026. The format provides a relational layer (this service connects to this case study, which connects to this clinical author) that goes deeper than llms.txt or standard schema.
Like llms.txt, OKF does not produce Google Search ranking lift directly, but it serves as the AI-agent-readable knowledge graph for non-Google surfaces.
We published one of the first OKF bundles in behavioral health marketing. The deeper read lives in our analysis of the Open Knowledge Format for treatment centers.
DEFINITION
MCP server (Model Context Protocol)
A callable API that lets AI agents query a facility’s data on demand. Where OKF is static (a published knowledge graph), MCP is dynamic (a queryable interface). Useful for facilities expecting agent-driven traffic over the next 24 months.
The MCP server sits at the highest end of the AI-specific surface stack. The implementation is more technical than llms.txt or OKF and requires development capacity that most treatment center operators do not currently have in-house.
Operators serious about the agentic-search horizon should consider an MCP server. Operators focused on the next 12 months of conventional AI Overviews and assistant citations can defer it.
The combined investment in the four AI-specific surfaces typically runs $8,000 to $25,000 in implementation cost, with ongoing maintenance minimal once shipped.
The right read on the investment is asymmetric: the cost is bounded, the upside compounds if AI search behaviors evolve as projected, and the downside is small if they do not.
PHASE 4 · MEASUREMENT
How to Track AI Citation Share Across Surfaces
Measurement is what separates the operators producing durable AI search lift from the operators running tactical experiments and hoping. The right framework tracks citation share across at least four AI surfaces.
The 3-step measurement setup most operators implement.
Baseline citation share
Run priority queries through ChatGPT, Claude, Perplexity, and Google AI Overviews. Document which sources get cited for each query.
Implement the stack
Ship the foundation, content, and infrastructure phases. Update the baseline measurement quarterly with the same query set.
Tie to admit attribution
Connect AI-search-driven visits to admit-attributed conversion in the CRM with 60- to 120-day attribution windows.
The baseline-citation-share step matters most. Operators who skip it cannot tell whether their AI citation work produced lift or whether they would have ranked the same without it.
The baseline can be manually compiled in a spreadsheet or, for larger operators, via Profound or one of the emerging AI citation tracking tools.
The quarterly review cadence is the right rhythm. AI citation behaviors shift faster than classic organic ranking shifts, but not so fast that monthly tracking adds signal. The quarterly review surfaces real movement and filters out noise.
PHASE 4 · MEASUREMENT
From Citation to Admit Attribution
Citation share is the upstream metric. Admit attribution is the metric that pays the bills. The connection between the two is what justifies the investment in the full stack.
The attribution pattern works in three layers. AI-search-driven visits to the facility’s site (tracked through referrer data, UTM tags where applicable, and direct-traffic uplift signals when an AI citation appears for a query the facility ranks for).
Inquiry conversions from those visits (tracked through call tracking, form submissions, and chat). Admits traced back through the CRM with 60- to 120-day windows that match the BH conversion cycle.
The measurement is not as clean as paid media attribution. AI surfaces do not always pass referrer data. Direct traffic uplift after an AI citation appears can take 30 to 60 days to materialize as the citation pattern stabilizes.
The right read is to use AI citation share as a leading indicator and admit attribution as the lagging confirmation, rather than expecting attribution to be deterministic per AI surface.
The Google AI Overviews and ChatGPT citation playbook covers the broader citation strategy frame. This article is the measurement context that sits underneath.
PHASE 4 · MEASUREMENT
Common Implementation Mistakes
The pattern across every treatment center AI search audit we run is consistent. Operators consistently get either the foundation right and the infrastructure wrong, or the infrastructure right and the foundation wrong, but rarely both right.
The strongest implementations across our client base come down to a small set of behaviors operators consistently get right or wrong.
WHAT WORKING AI SEARCH STACKS DO
- Named clinical author and reviewer on every YMYL article
- Hub-and-spoke architecture with deliberate internal linking
- Non-commodity content built on first-hand clinical perspective
- Quarterly AI citation share baseline + admit attribution
- AI-specific surfaces sized to the non-Google AI horizon
WHAT BROKEN AI SEARCH STACKS SKIP
- Editorial Team bylines on YMYL content
- Chronological /blog/ feed with no hub pages
- Commodity 7-Tips and listicle content
- No citation tracking, no attribution windows
- llms.txt and OKF expected to lift Google ranking
Most facilities have two or three of these mistakes in their current implementation. Closing them in sequence produces the compounding lift the stack is designed to deliver.
The order matters: foundation first, content second, infrastructure third, measurement fourth. Reversing the order or skipping the foundation produces 12 months of tactical work with no measurable lift.
Frequently Asked Questions
Where should an operator start if they have not done any of this work yet?
Start with the foundation phase. E-E-A-T (named clinical authorship, structured author bios, peer-reviewed citations) plus the technical SEO baseline (Core Web Vitals, schema, internal linking) are the layers everything else compounds on. Operators who skip the foundation and start with llms.txt or OKF produce expensive surface work that does not have content to point at.
The first 30 days should rebuild author bylines and reviewer credit across the existing library. The next 30 days should ship the schema stack (Organization, MedicalOrganization, Article with Person author, FAQPage, BreadcrumbList). After that, the content layer compounds for the next 6 to 12 months and the infrastructure surfaces become net-additive rather than load-bearing.
The sequencing matters more than the speed. A facility that ships foundation by month 3, content cluster expansion by month 9, and full infrastructure by month 12 outperforms a facility that tries to ship all four phases in parallel at month 1.
How long does the full stack take to produce results?
First measurable lift typically shows up at 60 to 90 days as the foundation phase lands. Cluster-wide AI citation share movement lands at 6 to 9 months as the content layer compounds. Admit-attributed conversion lift lands at 9 to 18 months as the full stack matures and the CRM attribution windows catch up.
The compounding effect is non-linear. The first 6 months produce roughly 30 percent of the total lift the stack will eventually deliver. The next 12 months produce the remaining 70 percent as the architecture is in place and the new content publishes into a strong foundation. Operators who quit at month 6 because the early lift looks modest miss the compounding curve entirely.
The right framing is 18 to 24 months for a full stack maturation. The work is durable once landed, but the timeline is not compressible without skipping phases.
Should an operator invest in llms.txt and OKF if Google does not use them for ranking?
Yes, but size the investment to the non-Google AI surface they actually influence. Google’s June 2026 guidance confirmed Google Search does not use llms.txt for ranking. ChatGPT, Claude, Perplexity, and emerging AI agents still read these surfaces, and citation share on those platforms is a growing share of high-intent treatment center traffic.
The combined investment in AI Information page + llms.txt + OKF + MCP server typically runs $8,000 to $25,000 in implementation cost. That cost is bounded. The upside compounds if AI search behaviors evolve as projected (more agentic, more retrieval-based, more cross-platform). The downside is small if they do not.
For most treatment center operators in the $50K to $250K monthly marketing spend range, the asymmetric payoff justifies the investment as long as it does not displace foundation work or content production cadence.
What’s the difference between an AI Information page and llms.txt?
The AI Information page is a human-readable, crawler-readable web page that disambiguates the facility’s identity (name, founding date, leadership, accreditations, services, locations). It sits at a URL on the site and is designed for AI systems to cite when generating responses about the facility. Operators control the content directly.
llms.txt is a plain-text site overview file at the root of the domain (mysite.com/llms.txt). Its job is to give AI crawlers a quick orientation to the site’s content structure, similar in spirit to robots.txt but for content navigation. It is shorter, more abstracted, and not a substitute for the AI Information page’s factual depth.
Operators ship both. The AI Information page is the factual source for entity disambiguation. llms.txt is the navigational hint for crawlers. They serve different jobs and the investment in each is small enough that picking one over the other does not change the economics.
How does this work with the existing paid media program?
The AI search stack is the organic counterpart to the paid media program, and the two compound when both are mature. Strong organic citation share lowers branded-query CPCs in paid (the facility shows up in Google AI Overviews for the same queries, reducing the perceived need to click on a paid ad). Strong paid conversion infrastructure makes organic traffic convert at the same rates paid traffic does.
The investment ratio depends on facility stage. New facilities (under 18 months of marketing maturity) should bias toward paid for early admits while the organic stack matures. Established facilities (3+ years of marketing maturity) typically run organic and paid at parity and use the compounding organic asset as the moat.
The wrong pattern is treating organic and paid as competing budgets. They serve different funnel positions and the combined ROI is materially higher than either in isolation. The right framing is ‘paid for the next 30 days, organic for the next 30 months.’
What about MCP servers and agentic search?
MCP (Model Context Protocol) servers are the highest-end surface in the stack and the most speculative investment. The thesis is that AI agents in the next 24 months will increasingly query facility data directly (insurance verification, bed availability, level-of-care fit) rather than read static pages. An MCP server is the callable interface that lets agents do that.
Operators serious about the agentic-search horizon should consider one. The implementation is more technical than llms.txt or OKF and typically requires developer capacity, which puts it out of reach for smaller facilities without an existing technical partner. Most current treatment center operators can defer the MCP investment for 12 to 18 months without missing the window.
The exception is facilities with strong technical capacity and a forward-looking marketing posture. For them, shipping an MCP server now is cheap insurance against the agentic-search shift and produces a differentiated infrastructure signal that competitors will not match for some time.
Ship the Foundation Before the Surfaces
The full AI search stack is real work. Four phases, sequenced, each compounding on the last. The operators producing durable lift are the operators who ship foundation first, then content, then infrastructure, then measurement.
The operators chasing the next shiny surface (whichever AI Overview citation tactic, llms.txt prompt format, or schema variant is being discussed in newsletters this week) without the foundation underneath produce 12 months of work with no compounding signal.
If your facility is evaluating where to start on the AI search stack or wants a sanity check on a stack already in motion, book an intro meeting with the Webserv team. We will diagnose which phase is the bottleneck and walk through the sequencing that produces real lift.
Trevor Gage is the Director of Marketing at Webserv. Webserv works with behavioral health and addiction treatment centers on SEO, paid media, and full-funnel admissions strategy.